
LCE: Don't play dice with random numbers
| LWN.net needs you! Without subscribers, LWN would simply not exist. Please consider signing up for a subscription and helping to keep LWN publishing |
H. Peter Anvin has been involved with Linux for more than 20
years, and is currently one of the x86 architecture maintainers. During his
work on Linux, one of his areas of interest has been the generation and use
of random numbers, and his talk at LinuxCon Europe 2012 was designed to
address a lot of misunderstandings that he has encountered regarding random
numbers. The topic is complex, and so, for the benefit of experts in the
area, he noted that "I will be making some
simplifications
". (In addition, your editor has attempted to fill
out some details that Peter mentioned only briefly, and so may have added
some "simplifications" of his own.)
Random numbers
Possibly the first use of random numbers in computer programs was for games. Later, random numbers were used in Monte Carlo simulations, where randomness can be used to mimic physical processes. More recently, random numbers have become an essential component in security protocols.
Randomness is a subtle property. To illustrate this, Peter displayed a
photograph of three icosahedral dice that he'd thrown at home, saying
"here, if you need a random number, you can use 846
". Why
doesn't this work, he asked. First of all, a random number is only random
once. In addition, it is only random until we know what it is. These
facts are not the same thing. Peter noted that it is possible to misuse a
random number by reusing it; this can lead to
breaches in security protocols.
There are no tests for randomness. Indeed, there is a yet-to-be-proved mathematical conjecture that there are no tractable tests of randomness. On the other hand, there are tests for some kinds non-randomness. Peter noted that, for example, we can probably quickly deduce that the bit stream 101010101010… is not random. However, tests don't prove randomness: they simply show that we haven't detected any non-randomness. Writing reliability tests for random numbers requires an understanding of the random number source and the possible failure modes for that source.
Most games that require some randomness will work fine even if the source of randomness is poor. However, for some applications, the quality of the randomness source "matters a lot".
Why does getting good randomness matter? If the random numbers used to generate cryptographic keys are not really random, then the keys will be weak and subject to easier discovery by an attacker. Peter noted a couple of recent cases of poor random number handling in the Linux ecosystem. In one of these cases, a well-intentioned Debian developer reacted to a warning from a code analysis tool by removing a fundamental part of the random number generation in OpenSSL. As a result, Debian for a long time generated only one of 32,767 SSH keys. Enumerating that set of keys is, of course, a trivial task. The resulting security bug went unnoticed for more than a year. The problem is, of course, that unless you are testing for this sort of failure in the randomness source, good random numbers are hard to distinguish from bad random numbers. In another case, certain embedded Linux devices have been known to generate a key before they could generate good random numbers. A weakness along these lines allowed the Sony PS3 root key to be cracked [PDF] (see pages 122 to 130 of that presentation, and also this video of the presentation, starting at about 35'24").
Poor randomness can also be a problem for storage systems that depend on some form of probabilistically unique identifiers. Universally unique IDs (UUIDs) are the classic example. There is no theoretical guarantee that UUIDs are unique. However, if they are properly generated from truly random numbers, then, for all practical purposes, the chance of two UUIDs being the same is virtually zero. But if the source of random numbers is poor, this is no longer guaranteed.
Of course, computers are not random; hardware manufacturers go to great lengths to ensure that computers behave reliably and deterministically. So, applications need methods to generate random numbers. Peter then turned to a discussion of two types of random number generators (RNGs): pseudo-random number generators and hardware random number generators.
Pseudo-random number generators
The classical solution for generating random numbers is the so-called pseudo-random number generator (PRNG):
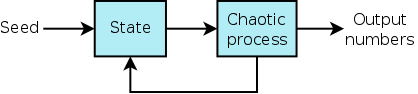
A PRNG has two parts: a state, which is some set of bits determined by a "seed" value, and a chaotic process that operates on the state and updates it, at the same time producing an output sequence of numbers. In early PRNGs, the size of the state was very small, and the chaotic process simply multiplied the state by a constant and discarded the high bits. Modern PRNGs have a larger state, and the chaotic process is usually a cryptographic primitive. Because cryptographic primitives are usually fairly slow, PRNGs using non-cryptographic primitives are still sometimes employed in cases where speed is important.
The quality of PRNGs is evaluated on a number of criteria. For example, without knowing the seed and algorithm of the PRNG, is it possible to derive any statistical patterns in or make any predictions about the output stream? One statistical property of particular interest in a PRNG is its cycle length. The cycle length tells us how many numbers can be generated before the state returns to its initial value; from that point on, the PRNG will repeat its output sequence. Modern PRNGs generally have extremely long cycle lengths. However, some applications still use hardware-implemented PRNGs with short cycle lengths, because they don't really need high-quality randomness. Another property of PRNGs that is of importance in security applications is whether the PRNG algorithm is resistant to analysis: given the output stream, is it possible to figure out what the state is? If an attacker can do that, then it is possible to predict future output of the PRNG.
Hardware random number generators
The output of a PRNG is only as good as its seed and algorithm, and while it may pass all known tests for non-randomness, it is not truly random. But, Peter noted, there is a source of true randomness in the world: quantum mechanics. This fact can be used to build hardware "true" random number generators.
A hardware random number generator (HWRNG) consists of a number of components, as shown in the following diagram:
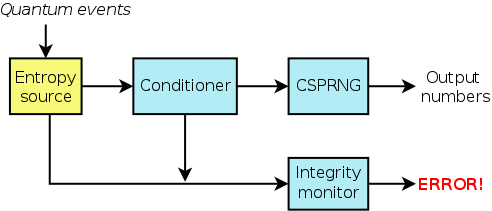
Entropy is a measure of the disorder, or randomness, in a system. An entropy source is a device that "harvests" quantum randomness from a physical system. The process of harvesting the randomness may be simple or complex, but regardless of that, Peter said, you should have a good argument as to why the harvested information truly derives from a source of quantum randomness. Within a HWRNG, the entropy source is necessarily a hardware component, but the other components may be implemented in hardware or software. (In Peter's diagrams, redrawn and slightly modified for this article, yellow indicated a hardware component, and blue indicated a software component.)
Most entropy sources don't produce "good" random numbers. The source may, for example, produce ones only 25% of the time. This doesn't negate the value of the source. However, the "obvious" non-randomness must be eliminated; that is the task of the conditioner.
The output of the conditioner is then fed into a cryptographically secure pseudo-random number generator (CSPRNG). The reason for doing this is that we can better reason about the output of a CSPRNG; by contrast, it is difficult to reason about the output of the entropy source. Thus, it is possible to say that the resulting device is at least as secure as a CSPRNG, but, since we have a constant stream of new seeds, we can be confident that it is actually a better source of random numbers than a CSPRNG that is seeded less frequently.
The job of the integrity monitor is to detect failures in the entropy source. It addresses the problem that entropy sources can fail silently. For example, a circuit in the entropy source might pick up an induced signal from a wire on the same chip, with the result that the source outputs a predictable pattern. So, the job of the integrity monitor is to look for the kinds of failure modes that are typical of this kind of source; if failures are detected, the integrity monitor produces an error indication.
There are various properties of a HWRNG that are important to users. One of these is bandwidth—the rate at which output bits are produced. HWRNGs vary widely in bandwidth. At one end, the physical drum-and-ball systems used in some public lottery draws produce at most a few numbers per minute. At the other end, some electronic hardware random number sources can generate output at the rate of gigabits per second. Another important property of HWRNGs is resistance to observation. An attacker should not be able to look into the conditioner or CSPRNG and figure out the future state.
Peter then briefly looked at a couple of examples of entropy sources. One of these is the recent Bull Mountain Technology digital random number generator produced by his employer (Intel). This device contains a logic circuit that is forced into an impossible state between 0 and 1, until the circuit is released by a CPU clock cycle, at which point quantum thermal noise forces the circuit randomly to zero or one. Another example of a hardware random number source—one that has actually been used—is a lava lamp. The motion of the liquids inside a lava lamp is a random process driven by thermal noise. A digital camera can be used to extract that randomness.
The Linux kernel random number generator
The Linux kernel RNG has the following basic structure:
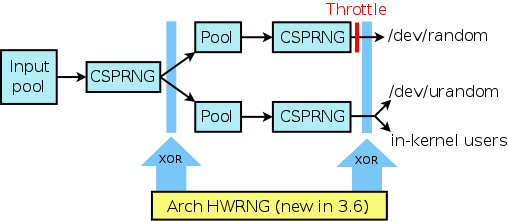
The structure consists of a two-level cascaded sequence of pools coupled with CSPRNGs. Each pool is a large group of bits which represents the current state of the random number generator. The CSPRNGs are currently based on SHA-1, but the kernel developers are considering a switch to SHA-3.
The kernel RNG produces two user-space output streams. One of these goes to /dev/urandom and also to the kernel itself; the latter is useful because there are uses for random numbers within the kernel. The other output stream goes to /dev/random. The difference between the two is that /dev/random tries to estimate how much entropy is coming into the system, and will throttle its output if there is insufficient entropy. By contrast, the /dev/urandom stream does not throttle output, and if users consume all of the available entropy, the interface degrades to a pure CSPRNG.
Starting with Linux 3.6, if the system provides an architectural HWRNG, then the kernel will XOR the output of the HWRNG with the output of each CSPRNG. (An architectural HWRNG is a complete random number generator designed into the hardware and guaranteed to be available in future generations of the chip. Such a HWRNG makes its output stream directly available to user space via dedicated assembler instructions.) Consequently, Peter said, the output will be even more secure. A member of the audience asked why the kernel couldn't just do away with the existing system and use the HWRNG directly. Peter responded that some people had been concerned that if the HWRNG turned out not to be good enough, then this would result in a security regression in the kernel. (It is also worth noting that some people have wondered whether the design of HWRNGs may have been influenced by certain large government agencies.)
The inputs for the kernel RNG are shown in this diagram:
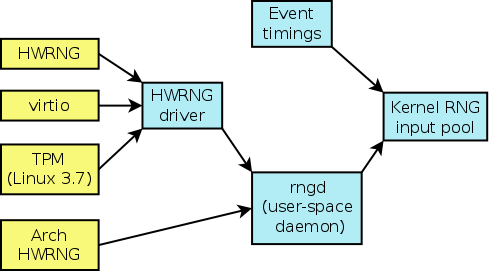
In the absence of anything else, the kernel RNG will use the timings of events such as hardware interrupts as inputs. In addition, certain fixed values such as the network card's MAC address may be used to initialize the RNG, in order to ensure that, in the absence of any other input, different machines will at least seed a unique input value.
The rngd program is a user-space daemon whose job is to feed inputs (normally from the HWRNG driver, /dev/hwrng) to the kernel RNG input pool, after first performing some tests for non-randomness in the input. If there is HWRNG with a kernel driver, then rngd will use that as input source. In a virtual machine, the driver is also capable of taking random numbers from the host system via the virtio system. Starting with Linux 3.7, randomness can also be harvested from the HWRNG of the Trusted Platform Module (TPM) if the system has one. (In kernels before 3.7, rngd can access the TPM directly to obtain randomness, but doing so means that the TPM can't be used for any other purpose.) If the system has an architectural HWRNG, then rngd can harvest randomness from it directly, rather than going through the HWRNG driver.
Administrator recommendations
"You really, really want to run rngd
", Peter
said. It should be started as early as possible during system boot-up, so
that the applications have early access to the randomness that it provides.
One thing you should not do is the following:
rngd -r /dev/urandom
Peter noted that he had seen this command in several places on the web. Its effect is to connect the output of the kernel's RNG back into itself, fooling the kernel into believing it has an endless supply of entropy.
HAVEGE
(HArdware Volatile Entropy Gathering and Expansion) is a piece of
user-space software that claims to extract entropy from CPU nondeterminism.
Having read a number of papers about HAVEGE, Peter said he had been unable
to work out whether this was a "real thing". Most of the papers that he
has read run along the lines, "we took the output from HAVEGE, and
ran some tests on it and all of the tests passed
". The problem with
this sort of reasoning is the point that Peter made earlier: there are no
tests for randomness, only for non-randomness.
One of Peter's colleagues replaced the random input source employed by
HAVEGE with a constant stream of ones. All of the same tests passed. In
other words, all that the test results are guaranteeing is that the HAVEGE
developers have built a very good PRNG. It is possible that HAVEGE does
generate some amount of randomness, Peter said. But the problem is that
the proposed source of randomness is simply too complex to analyze; thus it
is not possible to make a definitive statement about whether it is truly
producing randomness. (By contrast, the HWRNGs that Peter described earlier
have been analyzed to produce a quantum theoretical justification that they
are producing true randomness.) "So, while I can't really recommend it, I
can't not recommend it either.
" If you are going to run HAVEGE,
Peter strongly recommended running it together with rngd,
rather than as a replacement for it.
Guidelines for application writers
If you are writing applications that need to use a lot of randomness, you really want to use a cryptographic library such as OpenSSL, Peter said. Every cryptographic library has a component for dealing with random numbers. If you need just a little bit of randomness, then just use /dev/random or /dev/urandom. The difference between the two is how they behave when entropy is in short supply. Reads from /dev/random will block until further entropy is available. By contrast, reads from /dev/urandom will always immediately return data, but that data will degrade to a CSPRNG when entropy is exhausted. So, if you prefer that your application would fail rather than getting randomness that is not of the highest qualify, then use /dev/random. On the other hand, if you want to always be able to get a non-blocking stream of (possibly pseudo-) random data, then use /dev/urandom.
"Please conserve randomness!
", Peter said. If you are
running recent hardware that has a HWRNG, then there is a virtually
unlimited supply of randomness. But, the majority of existing hardware
does not have the benefit of a HWRNG. Don't use buffered I/O on
/dev/random or /dev/urandom. The effect of performing a
buffered read on one of these devices is to consume a large amount of the
possibly limited entropy. For example, the C library stdio
functions operate in buffered mode by default, and an initial read will
consume 8192 bytes as the library fills its input buffer. A well written
application should use non-buffered I/O and read only as much randomness as
it needs.
Where possible, defer the extraction of randomness as late as possible in an application. For example, in a network server that needs randomness, it is preferable to defer extraction of that randomness until (say) the first client connect, rather extracting the randomness when the server starts. The problem is that most servers start early in the boot process, and at that point, there may be little entropy available, and many applications may be fighting to obtain some randomness. If the randomness is being extracted from /dev/urandom, then the effect will be that the randomness may degrade for a CSPRNG stream. If the randomness is being extracted from /dev/random, then reads will block until the system has generated enough entropy.
Future kernel work
Peter concluded his talk with a discussion of some upcoming kernel work. One of these pieces of work is the implementation of a policy interface that would allow the system administrator to configure certain aspects of the operation of the kernel RNG. So, for example, if the administrator trusts the chip vendor's HWRNG, then it should be possible to configure the kernel RNG to take its input directly from the HWRNG. Conversely, if you are paranoid system administrator who doesn't trust the HWRNG, it should be possible to disable use of the HWRNG. These ideas were discussed by some of the kernel developers who were present at the 2012 Kernel Summit; the interface is still being architected, and will probably be available sometime next year.Another piece of work is the completion of the virtio-rng system. This feature is useful in a virtual-machine environment. Guest operating systems typically have few sources of entropy. The virtio-rng system is a mechanism for the host operating system to provide entropy to a guest operating system. The guest side of this work was already completed in 2008. However, work on the host side (i.e., QEMU and KVM) got stalled for various reasons; hopefully, patches to complete the host side will be merged quite soon, Peter said.
A couple of questions at the end of the talk concerned the problem of live cloning a virtual machine image, including its memory (i.e., the virtual machine is not shut down and rebooted). In this case, the randomness pool of the cloned kernel will be duplicated in each virtual machine, which is a security problem. There is currently no way to invalidate the randomness pool in the clones, by (say) setting the clone's entropy count to zero. Peter thinks a (kernel) solution to this problem is probably needed.
Concluding remarks
Interest in high-quality random numbers has increased in parallel
with the increasing demands to secure stored data and network
communications with high-quality cryptographic keys. However, as various
examples in Peter's talk demonstrated, there are many pitfalls to be wary
of when dealing with random numbers. As HWRNGs become more prevalent, the
task of obtaining high-quality randomness will become easier. But even if
such hardware becomes universally available, it will still be necessary to
deal with legacy systems that don't have a HWRNG for a long
time. Furthermore, even with a near infinite supply of randomness it is
still possible to make subtle but dangerous errors when dealing with random
numbers.
| Index entries for this article | |
|---|---|
| Kernel | Random numbers |
| Security | Random number generation |
| Conference | LinuxCon Europe/2012 |
(Log in to post comments)
LCE: Don't play dice with random numbers
Posted Nov 20, 2012 18:31 UTC (Tue) by dd9jn (✭ supporter ✭, #4459) [Link]
LCE: Don't play dice with random numbers
Posted Nov 20, 2012 18:59 UTC (Tue) by kpfleming (subscriber, #23250) [Link]
LCE: Don't play dice with random numbers
Posted Nov 20, 2012 19:59 UTC (Tue) by mkerrisk (subscriber, #1978) [Link]
LCE: Don't play dice with random numbers
Posted Nov 20, 2012 19:48 UTC (Tue) by nim-nim (subscriber, #34454) [Link]
> rngd[1938]: No entropy sources working, exiting rngd
Seems the tpm part is not foolproof yet. And me foolishly thinking I could use this chip for something at last…
LCE: Don't play dice with random numbers
Posted Nov 20, 2012 20:40 UTC (Tue) by nock (guest, #46168) [Link]
LCE: Don't play dice with random numbers
Posted Nov 21, 2012 0:59 UTC (Wed) by hpa (guest, #48575) [Link]
LCE: Don't play dice with random numbers
Posted Nov 21, 2012 6:22 UTC (Wed) by nim-nim (subscriber, #34454) [Link]
3.7.0-0.rc6.git1.1.fc19.x86_64
Good piece
Posted Nov 20, 2012 20:54 UTC (Tue) by man_ls (guest, #15091) [Link]
Fascinating stuff. A few comments.The period of pseudo-random number generators tends to be very, very high; so much so that they will produce repeated results much less frequently than a random source (in practice this difference is not easy to exploit). It is good to test for a large number of inputs that numbers do not repeat -- after the Debian fiasco, 2^16 times is an absolute minimum.
Speaking of which: randomness tests are a funny thing. Weird results are practically guaranteed if you run the tests long enough: deviations appear every once in a while. If you remove outliers (to maintain randomness), then you are in effect removing a bit of entropy. Imagine if I said that my 32-bit generator cannot in fairness generate a number with more than 24 bits set to 0 or to 1 -- this situation would arise with a pure random source every 2^8=256 times or so. If I remove these numbers then I am culling the output of my generator and therefore weakening it. I am concerned about vulnerabilities not only in the entropy source, but in the conditioner or in the integrity monitor.
Randomness is not only found in quantum mechanics; classical mechanics contains plenty of randomness, e.g. in a perfect gas, brownian movement, or thermal fluctuations, or even radio static... But classical noise tends to be more "analog" and therefore harder to calibrate, while quantum mechanics lends itself better to digitization.
The part about HAVEGE leaves more questions than answers. How come the stream of 1's passed the tests, what kind of feeble-minded testsuite was it? Is it safe to use HAVEGE in production, or not? Even what is HAVEGE is not answered; the comments to this article explain it very well (unless you may find it muddied by my comments and others').
Do paranoid fears about hardware backdoors have any basis? Schenier's piece linked in the article is from 2007 and it speaks about a real backdoor built into DRBGs by the NSA itself; I am not sure if doing the same with hardware is even possible. Aren't there better, more recent references?
All in all, an in-depth article about randomness is well justified, IMHO.
Good piece
Posted Nov 20, 2012 21:42 UTC (Tue) by epa (subscriber, #39769) [Link]
Good piece
Posted Nov 20, 2012 21:46 UTC (Tue) by dlang (guest, #313) [Link]
If the tests can't tell the difference between it being fed all '1's and random input, then the tests are pretty worthless in terms of evaluating it.
Remember that the claim is that this is far better than a PRNG by itself, so to show this, you need to have a test that fails on a PRNG, but passes with the HAVEGE hardware input.
Either that or you need to explain why HAVEGE is better, not just say "see, we studied it and it passed all the tests", which is what HPA is complaining that most of the papers on it boil down to.
Good piece
Posted Nov 20, 2012 22:02 UTC (Tue) by mkerrisk (subscriber, #1978) [Link]
> being fed all '1's and random input, then the
> tests are pretty worthless in terms of evaluating it.
To be clear: it is not the *tests* that are being fed all 1s. It is HAVEGE, which then anyway produces good enough PRNG outputs that the test pass.
Good piece
Posted Nov 20, 2012 21:42 UTC (Tue) by dlang (guest, #313) [Link]
If you flip a (fair) coin and it lands head 8 times in a row (a 1 in 256 chance), what are the odds of it landing heads the next time.
if it's really a fair coin, the chance is 1 in 2
If you are getting a 8 bit value, the chances of getting the exact same number the next time you get a value are 1 in 256.
If you change your system so that you guarantee that you don't get that same number twice within 128 tries, you will have seriously hurt the randomness of your results
*Secure* randomness
Posted Nov 21, 2012 12:39 UTC (Wed) by kirkengaard (guest, #15022) [Link]
If all we want is pure randomness, and we don't rely on it for anything, any non-patterned output, however often it may reproduce specific values in its output, is sufficient. A d6, for example, or a coin.
But if what we want is *secure* randomness over long cycles, then repeating entries is bad. Collisions are breaches waiting to happen. Even if the sequence doesn't repeat, if I know enough of the output, I can wait.
Strings of 1s may happen with a two-state generator, for example, but the point of running them through much more complicated chains, to generate "more" randomness, is really also to generate more *usefully secure sequences* (that is, non-repetitive) of random numbers. Which is why also the filtering and throttling and whatnot.
Good piece
Posted Nov 28, 2012 16:49 UTC (Wed) by akeane (guest, #85436) [Link]
>if it's really a fair coin, the chance is 1 in 2
Yep, and it's amazing how many well educated numerate people don't get this (I once had a friend who was an astrophysicist who thought tails was more likely)
The way I explain it is this, the coin doesn't have a memory or a conscience, it just reacts to a bunch of forces which are hard to predict, and have been around since that Newton fellow invited gravity in 1964.
111111111 is just as likely as 100110100 etc, it's just that people recognize or interpret the 111111111 as a pattern and think, wow what are the chances of that...
111111111 is just as random a number as anything else because you can't predict the tenth flip.
Now if the coin landed on it's side 10 times in a row...
If you really want to wind somebody up (and I generally do) try telling someone who works in the financial industry to plot a histogram of the daily percentage movements for the last 25 years of the SP500, of the FTSE all share and ask what curve they get :-)
Then ask what their commission is actually buying you!
Good piece
Posted Nov 28, 2012 20:05 UTC (Wed) by mathstuf (subscriber, #69389) [Link]
Huh, I didn't know you could invite gravity anywhen.
Good piece
Posted Dec 1, 2012 21:55 UTC (Sat) by akeane (guest, #85436) [Link]
That's OK, my simple colonial friend, don't be ashamed of your ignorance, back in the old country we used to invent stuff all the time, behold: friction co-efficients, the lingua franca, owls and even the concept of pitying fools. Although the last one was purloined ("nicked" as we say in the modern parlance) by a mo-hawked maniac who had an unhealthy obsession with his "van"...
Note that I am not including calculus in this analysis as even the most bereft of brain molecules can clearly see it's naught more than filthy hack, the universe should be modeled with integers, or at least BCD.
Divide h plus a bit by h, tut!
Good piece
Posted Dec 5, 2012 19:38 UTC (Wed) by jrigg (guest, #30848) [Link]
> Huh, I didn't know you could invite gravity anywhen.
You can if the invitation is posthumous by 237 years ;-)
Good piece
Posted Nov 29, 2012 1:40 UTC (Thu) by cb064 (guest, #88059) [Link]
PS: for anybody interested:
https://www.student.gsu.edu/~gconnaughton1/Project2.htm
If i had plenty of time if would probably read: http://upetd.up.ac.za/thesis/available/etd-03122010-16481...
Good piece
Posted Dec 2, 2012 11:35 UTC (Sun) by akeane (guest, #85436) [Link]
Rather than suppose why not try, the data is all there, it takes a few lines of a bash script to download the data (stuff that actually exists rather than supposition), do the counting and produce a csv file you can put into whatever graphing tool you like and see what you get?
And if you can't be bothered to do that, don't start whining when your pension or 401k plan, doesn't "perform" like you were told...
:-)
Good piece
Posted Nov 20, 2012 22:23 UTC (Tue) by wolfgang (subscriber, #5382) [Link]
> contains plenty of randomness, e.g. in a perfect gas, brownian movement,
> or thermal fluctuations, or even radio static... But classical noise
> tends to be more "analog" and therefore harder to calibrate, while
> quantum mechanics lends itself better to digitization.
Classical mechanics is by definition a deterministic theory (irreversibility only comes into play with statistical mechanics, which is an effective approximation of classical mechanics for very large systems), and strictly speaking, no randomness can be gained in this framework at all. Systems may /seem/ random, but this randomness is only epistemological, caused by insufficient knowledge about the (initial conditions of the) system. Quantum mechanics, on the other hand, is able to describe ontological randomness. This is not influenced by the dimension of the Hilbert space under consideration, which roughly translates into "analog" or "discrete" systems: A finite-dimensional quantum system can contain randomness that stems exclusively from the mixedness of the state, and an infinite-dimensional quantum system can be a perfect provider of randomness (the vacuum state of an electromagnetic field is one particularly convenient possibility, for instance).
Since the measurement process is invariably classical in nature with current-day technology, it is also impossible to produce perfect randomness even with perfect quantum systems -- the measurement noise will always influence the result. However, there are fortunately means of distilling nearly perfect randomness given knowledge about the entropy (or, to be precise, the conditional min-entropy) of the measured state, given some initial amount of nearly perfect randomness as seed.
Good piece
Posted Nov 20, 2012 22:41 UTC (Tue) by man_ls (guest, #15091) [Link]
Yes, my examples are mostly based on statistical mechanics, which provides a nice framework to generate randomness. But I disagree about this part:Systems may /seem/ random, but this randomness is only epistemological, caused by insufficient knowledge about the (initial conditions of the) system.In fact the second law of thermodynamics (which incidentally was postulated before the first) ensures that knowledge about the system will degrade in time, so even if perfect information is held at the start, any system will quickly degrade into random patterns. It is not an artifact of our limitations, but an essential principle of nature. We will never be able to predict the minute variations in thermal noise, no matter how much we know about the system.
As for macroscopic randomness, the humble three-body problem in gravitation generates a chaotic system using only classical equations: minor deviations cause major, unpredictable changes in the system.
Good piece
Posted Nov 20, 2012 23:10 UTC (Tue) by wolfgang (subscriber, #5382) [Link]
> postulated before the first) ensures that knowledge about the system will
> degrade in time, so even if perfect information is held at the start, any
> system will quickly degrade into random patterns. It is not an artifact of
> our limitations, but an essential principle of nature. We will never be
> able to predict the minute variations in thermal noise, no matter how much
> we know about the system.
Thermodynamics implies that a reservoir is involved in the modelling of a physical process, and that this reservoir is only treated effectively (any degrading system implies such a reservoir; otherwise, there would be nothing it could degrade into). If all parts of the system were treated with the dynamical laws of classical mechanics, it would not be necessary to fall back to a thermodynamic approximation. There would also be no reservoir.
So using a reservoir to model a physical system amounts to a lack of knowledge, which in turn causes the perceived randomness.
> As for macroscopic randomness, the humble three-body problem in
> gravitation generates a chaotic system using only classical equations:
> minor deviations cause major, unpredictable changes in the system.
A chaotic system is by its very definition a deterministic system. Initially close states may diverge arbitrarily far by temporal propagation (loosely spearking; things become more involved when the associated phase space volume can shrink), but the individual trajectories are still governed by deterministic dynamics.
They are very well predictable. If the initial conditions could be determined with infinite accuracy -- which, in the framework of classical mechanics, is theoretically possible -- there is no randomness involved.
But admittedly, these considerations are for the /really/ paranoid. Solving coupled dynamical equations of 10**23 or so particles certainly presents a /tiny/ practical problem ;)
Perfect information
Posted Nov 21, 2012 9:08 UTC (Wed) by man_ls (guest, #15091) [Link]
The second law of thermodynamics is not a consequence of reservoirs; they are just an artifact introduced to model and simplify the outside world, since the second law works just as well without them.It goes a bit further than that: perfect information about any system is unattainable in classical mechanics. Infinite bits would be needed just to keep the state of a single particle, let alone 10^23 of them, let alone placing them in a non-linear system, let alone computing anything beyond a perfect gas. No matter how paranoid you are, modeling a real world gas particle by particle is not feasible.
In fact, a modern information-theoretic formulation of the second law would say that "to extract one bit of information from a system you have to reduce its entropy in one bit", which explains why perfect information about systems cannot be achieved. Many people believe that only quantum mechanics say that "observation modifies the system being observed", but it is not so.
To find a formulation to which both of us can agree, we might say that "classical mechanics has an element of randomness unless we have perfect information about a system; perfect information cannot be achieved; therefore classical mechanics is random in nature".
Good piece
Posted Nov 25, 2012 5:58 UTC (Sun) by rgmoore (✭ supporter ✭, #75) [Link]
A chaotic system is by its very definition a deterministic system. Initially close states may diverge arbitrarily far by temporal propagation (loosely spearking; things become more involved when the associated phase space volume can shrink), but the individual trajectories are still governed by deterministic dynamics. They are very well predictable. If the initial conditions could be determined with infinite accuracy -- which, in the framework of classical mechanics, is theoretically possible -- there is no randomness involved.
Sure, but that doesn't describe the real world. The real world exhibits quantum behaviors, and classical mechanics is just a simplifying assumption. We can't know the exact initial position and momentum for every particle in a system; our knowledge is limited by the Uncertainty Principle. Even if we could somehow bypass the Uncertainty Principle and determine objects' initial states perfectly, it wouldn't necessarily get us anything. There are other quantum effects that are truly random, like spontaneous emission of infrared photons from molecules that are in excited vibrational states. As long as a system is chaotic by classical mechanics, those real world quantum effects will guarantee that it is truly unpredictable.
Good piece
Posted Nov 27, 2012 0:12 UTC (Tue) by wolfgang (subscriber, #5382) [Link]
Uncertainty principle
Posted Nov 28, 2012 12:45 UTC (Wed) by tialaramex (subscriber, #21167) [Link]
The principle is often misunderstood as a limitation on our observations of a system that really has properties like "exact momentum" and "precise location" - just like the observer effect in classical mechanics. Indeed it is sometimes explained this way in high school or in pop science books. That's not what's going on! The Uncertainty Principle actually says that these properties _do not exist_ not that we have some trouble measuring them. We can do experiments which prove that either an electron does not actually _have_ a specific position when its momentum is known or else that position is somehow a hidden property of the entire universe and not amenable to our pitiable attempts to discover it in the locale of the actual electron. The Uncertainty Principle says that the former is the more plausible explanation (and certainly the only one that's consistent with the remainder of our understanding about how the universe "works").
Uncertainty principle
Posted Nov 29, 2012 18:02 UTC (Thu) by davidescott (guest, #58580) [Link]
For a descriptive theory I would personally prefer determinism and non-locality. For a predictive theory non-determinism and locality are clearly better.
Good piece
Posted Nov 29, 2012 17:47 UTC (Thu) by davidescott (guest, #58580) [Link]
a) Classical Mechanics (as described by Newton) is NOT deterministic. See "Space Invaders" or for an example without infinities (but a non-differentiable surface) John D. Norton's work. http://plato.stanford.edu/entries/determinism-causal
b) When you claim that QM is non-deterministic you appear to be assuming the Copenhagen interpretation. From a Bohmian perspective QM may still be deterministic, but forever beyond our powers to make a deterministic prediction of its behavior, because of its disturbing non-locality.
Saying that QM processes provide a true source of randomness is really the "Church's thesis" of cryptography. Its hard to see (given our current knowledge of physics) how we could ever arrive at a useful definition of "randomness" that was in any way stronger than what we get by saying that "QM processes are random". In other words when you say that a QM process is truly random you are defining "randomness" not ascribing a property to QM processes.
Good piece
Posted Nov 29, 2012 18:33 UTC (Thu) by Cyberax (✭ supporter ✭, #52523) [Link]
1) "Space invaders" scenario is perfectly deterministic, they just have a problem with incorrect abstraction. In particular, treating gravity as infinitely fast. If we instead treat gravity as a classical field with finite interaction propagation speed, then this paradox disappears. Ditto for special relativity (it has its own problems with singularities, though).
2) Even if we allow the "space invaders" it still does NOT mean the system is not deterministic. If we know all the details about the system then we can predict its behavior with arbitrary precision. That knowledge, of course, must include all the infinitely fast objects. Laplace demon is still able to predict everything with arbitrary precision.
Good piece
Posted Nov 29, 2012 20:45 UTC (Thu) by man_ls (guest, #15091) [Link]
You are aware that Laplace's demon (as Maxwell's) is nothing short of God-like in nature. And that its very nature was refuted (as seen in Wikipedia) by the second law of Thermodynamics:According to chemical engineer Robert Ulanowicz, in his 1986 book Growth and Development, Laplace's demon met its end with early 19th century developments of the concepts of irreversibility, entropy, and the second law of thermodynamics. In other words, Laplace's demon was based on the premise of reversibility and classical mechanics; however, under current theory, thermodynamics (i.e. real processes) are thought to be irreversible in practical terms (compared to the age of the universe, for instance).Apparently this last part has not been stated convincingly enough since I brought it up several comments up, and it is indeed hard to grasp. The consequence is that no entity can predict what will happen in a system with absolute precision, not even a theoretical demon, not even in theory. In theory the amount of information that can be stored is always limited, so that (to state it in modern terms) below the noise level the signal is unpredictable. And the noise level cannot be made arbitrarily small.
Good piece
Posted Dec 4, 2012 22:31 UTC (Tue) by chithanh (guest, #52801) [Link]
And the second law of thermodynamics has been refuted by Poincaré recurrence.
Good piece
Posted Dec 5, 2012 8:35 UTC (Wed) by man_ls (guest, #15091) [Link]
Hardly a rebuttal since this theorem and the second law operate on different time scales. Boltzmann had a similar argument for the whole universe; it only made the second law stronger.Whenever something contradicts the second law, that something loses. But if you feel better with a recurrence every 10^10^100... seconds or so, then so be it.
Good piece
Posted Dec 5, 2012 21:25 UTC (Wed) by mathstuf (subscriber, #69389) [Link]
And don't fret, those 10's are rounded up from e, so it's not as long as it might seem (though I think you're missing few stacks and should be 10^10^10^10^10^1.1).
Good piece
Posted Dec 5, 2012 21:38 UTC (Wed) by man_ls (guest, #15091) [Link]
You are right, I added the ellipsis on a Googolplex because I could not find any good estimate at the moment. Now I have: in the Wikipedia no less, and it is as you say. Saying it is bigger than the age of the universe is a bit of an understatement. So don't hold your breath for a recurrence.Besides, it would only happen if our universe is an energy-conserving system; probably just changing size would break the recurrence.
Finally, even if a recurrence was possible in an expanding universe, it would just leave us at the starting point; not just diminish the entropy.
Good piece
Posted Nov 29, 2012 21:13 UTC (Thu) by davidescott (guest, #58580) [Link]
You are moving the bar and no longer talking about classical mechanics.
We know classical mechanics is not the correct theory, the point is that one of the ways it is incorrect is that it allows for mathematical singularities in its solutions. If you start slapping restrictions on the theory: "finite force propagation, energy and speed limits, regularity of solutions, continuity of fields, etc...." to prevent those singularities from appearing then it is no longer classical mechanics. It is something else.
> If we know all the details about the system then we can predict its behavior with arbitrary precision. That knowledge, of course, must include all the infinitely fast objects.
Again you aren't talking about Classical Mechanics. Your Demon wants to predict what will happen to the ball at time t_2, and wants to make that prediction based on the state of the universe at time t_0. Suppose that the correct prediction is "the ball does not exist at time t_2, because an Invader appears at time t_1 \in (t_0, t_2) and vaporizes the ball before t_2." If your Demon is capable of making such a prediction then he/she must be able to:
Express in the notation of classical Newtonian mechanics the position and velocity of the Space Invader at time t_0, so that I can deterministically show that the invader MUST begin to slow at time t_1 and destroy the ball prior to time t_2.
You CANNOT do so because v=infinity and x=everywhere (or x=emptyset) is not a valid expression of position and velocity of a body in Newtonian Mechanics. In Newton's formulas, the infinitely fast object DOES NOT EXIST within the classical universe, but his formulas allow it to be the finite-time limit of a classical process.
Good piece
Posted Nov 29, 2012 21:36 UTC (Thu) by Cyberax (✭ supporter ✭, #52523) [Link]
Yup.
>Suppose that the correct prediction is "the ball does not exist at time t_2, because an Invader appears at time t_1 \in (t_0, t_2) and vaporizes the ball before t_2." If your Demon is capable of making such a prediction then he/she must be able to
It must be able to integrate equations of motion. That's all.
>Express in the notation of classical Newtonian mechanics the position and velocity of the Space Invader at time t_0, so that I can deterministically show that the invader MUST begin to slow at time t_1 and destroy the ball prior to time t_2.
Wrong. "Space invader" exists only at ONE point - it has infinite speed and can't slow down.
>You CANNOT do so because v=infinity and x=everywhere (or x=emptyset) is not a valid expression of position and velocity of a body in Newtonian Mechanics. In Newton's formulas, the infinitely fast object DOES NOT EXIST within the classical universe, but his formulas allow it to be the finite-time limit of a classical process.
Newtonian mechanics has no problems with infinitely fast objects, as long as you don't collide them with something else.
That makes them a little bit like black holes - they are singularities, but they are fairly well-behaved
Good piece
Posted Nov 29, 2012 23:21 UTC (Thu) by davidescott (guest, #58580) [Link]
WHAT?
If you think that is the case solve the following single particle 1-dimensional, force-less system:
t=0: the particle is "at" x=0 and has dx/dt=\infty and d^2x/dt^2=0.
Solve for t=1 to get x_1,v_1,a_1
Now solve the following systems for t=1 and t=-1:
t=0: x=x_1, dx/dt=-v_1, d^2x/dt^2=a_1
t=0: x=2*x_1, dx/dt=-v_1, d^2x/dt^2=a_1
t=0: x=x_1, dx/dt=-2*v_1, d^2x/dt^2=a_1
t=0: x=2*x_1, dx/dt=-2*v_1, d^2x/dt^2=a_1
Either you cannot do this, or something will be contradictory.
Good piece
Posted Nov 30, 2012 0:33 UTC (Fri) by Cyberax (✭ supporter ✭, #52523) [Link]
Good piece
Posted Nov 30, 2012 2:18 UTC (Fri) by davidescott (guest, #58580) [Link]
Good piece
Posted Nov 30, 2012 7:07 UTC (Fri) by apoelstra (subscriber, #75205) [Link]
This isn't the problem with space invaders, though. The problem is that you have an object that disappears to infinity, where it remains for all time. But since classical mechanics is time-reversible, it could just-as-legitimately said that the object "has been at infinity since eternity, then moves to a finite position at time t".
But nothing in classical mechanics predict when "time t" is, hence the indeterminacy.
As you have pointed out, special relativity wrecks up this pathology (though general relativity introduces many more, much worse, ones). But that's irrelevant to whether the claim "classical mechanics is deterministic" is true.
Good piece
Posted Nov 30, 2012 14:07 UTC (Fri) by davidescott (guest, #58580) [Link]
Good piece
Posted Nov 29, 2012 20:55 UTC (Thu) by man_ls (guest, #15091) [Link]
Its hard to see (given our current knowledge of physics) how we could ever arrive at a useful definition of "randomness" that was in any way stronger than what we get by saying that "QM processes are random".I disagree. Information theory can indeed provide a definition of randomness: a signal with maximum entropy, where each bit of the signal carries one bit of information. In a normal text different bits are correlated and therefore the information content is always less than one bit per bit of signal.
Going from there to quantum processes is not easy, but I would say that it equates to "quantum events are not correlated in time with previous events, only with states". This means that the probability of emitting a photon at any given moment is the same, regardless of the time that the photon was absorbed; only the state of the particle is relevant, not its history. Since the time when the photon is emitted is not correlated with the moment that it was absorbed, this time is random and therefore impossible to predict.
Good piece
Posted Nov 29, 2012 22:24 UTC (Thu) by davidescott (guest, #58580) [Link]
I'm someone who things it very strange when people talk about wave-form collapse, and even stranger when some physicists talk about many worlds (in the universes are duplicated to realize all possible outcomes sense). As if the way to deal with our limited ability to measure the universe around us is by assuming it to be random, and then even more perversely to correct this "God does not play dice" problem by presuming that all outcomes occur in the correct probabilities.
To me it makes much more sense to say. The Universe IS. There is no such thing as "wave-form collapse" or even "wave function evolution." There is no such thing as "time." A excitation exists in some 4 dimensional space. It has a particular shape and you can take cross-sections of it along various planes and compute quantities such as Energy or Charge that happen to be conserved across that class of cross-sections. There are even descriptions of the dynamics of excitation as you continuously vary the cross-section taken. We happen to call one of these local descriptions the Copenhagen interpretation of QM, it is probabilistic and non-deterministic. There is non-local description of the same dynamics, Bohmian QM, it is deterministic.
We use the Copenhagen interpretation because we are interested in the predictive capability of the theory, which Bohmian QM just can't do. If Bohmian QM predicts spin up and its spin down the scientist says "there was a non-local reaction with something outside the experimental apparatus that affected the hidden variable which I can never measure directly." You can start playing games with things and saying I have 99% confidence the hidden variable value is up, and a 99.999% confidence that no non-local interaction will affect that, but its no advantage over Copenhagen, and just saying the outcome is UP 98.999% of the time.
But being predictive IS NOT the same as being descriptive. Don't tell me something *IS* (in the descriptive sense) random just because you can't predict the next number. That's not randomness that just limited intelligence, mathematical ability, and computational capability. Pick an arbitrary sequence from OEIS.org or some sample from the digits of PI and ask people if it is random. NOBODY will say: Oh that's PI beginning at digit 288342341234, but that doesn't make it random. That makes us dumb.
------------------------------------------------------------------
So to the particulars of your comments:
> a signal with maximum entropy, where each bit of the signal carries one bit of information.
"1" was that random or not? Can't say... I need to talk about a sequence of digits.
"3.14159"? -- not random that is "PI."
I don't know what PI is can you explain it to me in less than 6 digits. If you cannot then you cannot compress the stream. If I gave you a thousand digits you could encode a C program that computes PI, but I don't know what C is so now you have to express that. What prevents me from playing the "what is a?" game all day long and forcing you to give me a complete description of every particle in a universe containing a computer that calculates "PI."
Finally we get to the indeterminate sequence of digits generated by your overvolted transistor. You claim that is random because the numbers generated by it cannot be compressed because the underlying process is quantum mechanical and thereby random.
I disagree. If you get to reference something outside the sequence like "PI" then so should I. I will thereby reference the output of your transistor in my deterministic non-local Bohmian description of the dynamics of our static universe. DONE. Its compressed. (self-referential, but compressed)
In other words I reject your statement that "quantum events are not correlated in time with previous events, only with states." I believe they are correlated because the universe has deterministic non-local dynamics, and hidden variables (if we could ever know them) would allow us to correlate the QM events over time.
Another way to put this is to say that you need multiple *INDEPENDENT* outputs from the process in order to calculate its entropy. I REJECT your ability to do so. There is no amount of time-space separation within this universe that you can put between multiple RNGs that will ever make them independent. You need multiple universes to get a correct calculation of entropy. You can only approximate entropy within a single universe.
That said when we calculate this approximate entropy, QM processes seem to have maximal entropy. That does not prove them to be random (descriptive) rather we predict them to be random. If the LHC starts pumping out particles that are all spin up, we would call that new physics and would have to adjust to a world where QM processes are no longer random.
Also the next digit in my sequence was 8, so it wasn't PI anyways.
Good piece
Posted Nov 30, 2012 0:30 UTC (Fri) by nybble41 (subscriber, #55106) [Link]
I think I see your problem. Without time, randomness is indeed impossible. There is no point in talking about random events when you can directly observe the entirety of space-time; from that perspective, there are no probabilities, only facts. This discussion, fortunately, was about a more human perspective, in which the past may be known but knowledge of the future is beyond our reach.
> If you get to reference something outside the sequence like "PI" then so should I. I will thereby reference the output of your transistor in my deterministic non-local Bohmian description of the dynamics of our static universe.
You can reference things outside of the sequence, but only if they are knowable before the sequence is generated. PI is known, being a fundamental mathematical constant, but the output of the transistor is not.
However, I would say that it is meaningless to talk about whether a specific _sequence_ is random; what matters is whether the _process_ of producing the sequence introduced new information into the system. (The same process must, of course, destroy some existing information in order that the entropy of the system as a whole remains monotonically increasing.)
If one can predict the result of a measurement with certainty using only information knowable beforehand, then the measurement itself introduces no new information, and thus is not random. Otherwise, the result of the measurement is random, with entropy greater than zero and less than or equal to the number of significant bits measured.
> Don't tell me something *IS* (in the descriptive sense) random just because you can't predict the next number.
It's not a question of whether you or I could predict the next number; the question is whether the rules of the system permit _anyone_ to predict the next number with 100% certainty, given all the information which it is possible for them to know. Even in a completely deterministic system it may not be possible, even in theory, for any one person to know all the initial conditions which can affect the result.
Good piece
Posted Nov 30, 2012 4:03 UTC (Fri) by davidescott (guest, #58580) [Link]
PI is just the limit of a sequence. It happens to be particularly useful in Mathematical theorems, but is it any less random because of that? Which of the following is not a random number, but a useful mathematical constant?
0.1039089930584351
0.2519318504932542
0.5772156649015328
0.6394164761104365
0.7741085613465057
0.9458817764941707
The number being recognizable is not a sufficient definition. Its like the old joke about the mathematician and the license plate. "KZJ-1249" what are the chances of seeing that! Every real number is special in its own way, but I agree the process is more important than the actual output. One wants to compare multiple instances of the same RNG process, recognizing that a true RNG almost never (but not never) outputs a sequence that is "obviously not random."
> I think I see your problem. Without time, randomness is indeed impossible.
In a some fundamental sense that is true. The larger point is that any deterministic system is "without time" in this sense, and that contrary to commonly held views Classical Mechanics is not deterministic, and QM can be deterministic.
So when people say QM is random, mechanics is not, they are usually assuming a non-deterministic interpretation of QM, which is not required by experimental evidence (only non-locality is required).
> the question is whether the rules of the system permit _anyone_ to predict the next number with 100% certainty, given all the information which it is possible for them to know
This is perhaps the closest to a meaningful definition of "random," but it depends upon the validity of the uncertainty principle, and who qualifies as _anyone_. It is in fact what I said earlier, that QM is how we define "random", not that QM *is* random.
In particular since physical law can never be proven complete and correct, "random" can never be proven to be correctly defined. QM is our best understanding of the rules of the system, and thus our current best standard for "randomness." If we find the rules to be wrong, and that the uncertainty principle is not fundamental to future models of physics then our definition of "random" will change, and something else might be brought forward as the standard for "randomness."
In this respect saying "QM is random" is vacuous, and is the same as saying "QM is our best understanding of physics." Before we had QM we had Brownian motion which could be have been appropriately called "random" although we now call it merely "chaotic."
Good piece
Posted Nov 30, 2012 8:47 UTC (Fri) by man_ls (guest, #15091) [Link]
This is perhaps the closest to a meaningful definition of "random," but it depends upon the validity of the uncertainty principle, and who qualifies as _anyone_.Why does this definition involve the uncertainty principle, at all? It depends on information theory alone: that the information held by any party is limited and can be computed.
Again, we go back to the beginning: the next number can be decided by a chaotic system (such as a coin toss), a statistical system (such as thermal noise), a truly quantum system (such as the spin of a particle in a pair) or just a clever adversary (as in cryptography). As long as the next number cannot be guessed by someone, it appears random. If the next number cannot be guessed by anyone (i.e. is not correlated to previous values), it is truly random. The difference is subtle but essential.
With this latest rehashing of the old deterministic conundrum I will leave the discussion, if you don't mind.
Good piece
Posted Nov 30, 2012 14:00 UTC (Fri) by davidescott (guest, #58580) [Link]
by the uncertainty principle. Uncertainty is why information is limited.
Uncertainty is the only reason (currently provided by physics) why we cannot propose the existence of an advanced species on another planet capable of mapping the positions and momenta of all particles in the universe.
If such a species existed then they would be able to correlate all outputs and nothing would be truly random.
Yes its determinism, but I don't see how it is a conundrum. Its all fairly straightforward. If there is determinism, and if there are no limits on information that can be gained about a system, then there are no "physical secrets" and no true randomness.
-----------------------------------------------------
My only point in bringing all this up was to correct wolfgang's false statements concerning the determinism of classical mechanics, the non-determinism of QM, and the supposed relationship between randomness and this non-determinism.
a) Classical Mechanics has no limits on information, but contrary to what many seem to believe it is not deterministic.
If Classical Mechanics were a true theory for the universe we could still define "truly random" values, by say counting the number of space invaders passing through a detector over a fixed time interval. This would be randomness deriving from the non-determinism of the universe.
Classical Mechanics is a provably false theory, and thankfully no space invaders have ever been seen.
b) QM has limits on information, and that alone is enough to define some notion of randomness. Contrary to what many seem to believe, QM is not non-deterministic. The Copenhagen interpretation is non-deterministic and very popular, but it is not the only interpretation. The Bohm interpretation is deterministic.
c) Your subtle differences are not lost on me. YOUR definition of random (random := next number cannot be guessed by anyone) is a definition based on the limits of information. It is crucial what "anyone" can do. Those limits are derived from the limits on what can be learned about other systems in the universe. It has absolutely nothing to do with determinism.
This definition is only correct if the uncertainty principle is not violated, which is why I say that "QM defines random" and not "QM is random". A Bohmian sees no randomness in the outcome of the quantum process, it is all predetermined. A Bohmian defines random as outcomes which are unpredictable due to the limits on information, which is again your definition.
--------------------------------------------------
Final remark. You state:
> If the next number cannot be guessed by anyone (i.e. is not correlated to previous values), it is truly random. The difference is subtle but essential.
I'm going to pick on your parenthetical remark. The definition proposed by the parenthetical "anything not correlated to previous values is truly random" is either false, or a bad definition (depending on exactly how it is read).
Bohmian QM is a system where outcomes can be unpredictable, but they are not in a philosophical sense "uncorrelated" because everything is mediated through hidden variables and is fully deterministic. This is nonsense to a Bohmian.
Or maybe this is a practical definition for a Copenhagenist (who believes in intrinsic randomness). Take the outputs and run them through an auto-correlation test. If they fail they are non-random, if they pass they are random. The problem here is that any auto-correlation test has a confidence interval, and has a false positive and false negative rate. Just because a RNG passes the auto-correlation test doesn't mean it isn't just psuedo-random with a long period so you got a false-negative, and just because an over-volted transistor fails a test doesn't mean it wasn't obeying QM, its just a false-positive.
Good piece
Posted Nov 30, 2012 17:00 UTC (Fri) by nybble41 (subscriber, #55106) [Link]
I just said that it's not the numbers which are random, but rather the process which produced them. Any of those numbers could be produced by a random process, or a universal constant useful in some context. The output of a random process could (with infinitesimal probability) be equal to PI to an arbitrary number of digits, and still be random; the output of a deterministic process with known initial conditions could be completely unrecognizable without actually repeating the process, and pass all the statistical heuristics for randomness, and yet the process would still not be random.
> The larger point is that any deterministic system is "without time" in this sense, and that contrary to commonly held views Classical Mechanics is not deterministic, and QM can be deterministic.
I'm not arguing with that. True randomness does not require non-determinism, provided no one can know all the initial conditions. The difference is that, given non-determinism, a process can be random even _with_ complete knowledge of the initial conditions.
>> the question is whether the rules of the system permit _anyone_ to predict the next number with 100% certainty, given all the information which it is possible for them to know
> This is perhaps the closest to a meaningful definition of "random," but it depends upon the validity of the uncertainty principle, and who qualifies as _anyone_. It is in fact what I said earlier, that QM is how we define "random", not that QM *is* random.
First, it doesn't depend on QM at all, or the uncertainty principle. QM (whether non-local or non-deterministic) is one system which defines cases where the number cannot be predicted, but it is hardly the only one. Classical mechanics also works, if the initial conditions are unknowable. Second, "anyone" simply means "anyone"; there are no qualifications.
> In particular since physical law can never be proven complete and correct, "random" can never be proven to be correctly defined.
Whether a physical process is random does depend on the physics of the process. If we're wrong about the physical laws, we may also be wrong about whether the process is random.
That doesn't really affect the definition of "random" so much as the system to which the definition is applied: what the system permits one to know, and whether that knowledge is sufficient to predict the next result given the system's rules.
Good piece
Posted Nov 30, 2012 17:30 UTC (Fri) by davidescott (guest, #58580) [Link]
Good piece
Posted Nov 21, 2013 14:24 UTC (Thu) by mirabilos (subscriber, #84359) [Link]
Care to explain to those non-USA people among us?
HAVEGE
Posted Nov 20, 2012 21:41 UTC (Tue) by ajb (guest, #9694) [Link]
HAVEGE
Posted Nov 20, 2012 22:24 UTC (Tue) by khim (subscriber, #9252) [Link]
Well, thank you Captain Obvious.
The question is not about source of randomness (contemporary CPUs are not asyncronous, but contemporary PCs as whole most certainly are asyncronous: memory access is just an obvious example), the question is how much if it is actually retained in the output, if any.
HAVEGE
Posted Nov 20, 2012 22:43 UTC (Tue) by ajb (guest, #9694) [Link]
HAVEGE
Posted Nov 28, 2012 16:53 UTC (Wed) by akeane (guest, #85436) [Link]
"Captain Obvious" is really funny though, I shall endeavor to use it more whilst conversing with minions!
LCE: Don't play dice with random numbers
Posted Nov 21, 2012 1:00 UTC (Wed) by geofft (subscriber, #59789) [Link]
Where possible, defer the extraction of randomness as late as possible in an application. For example, in a network server that needs randomness, it is preferable to defer extraction of that randomness until (say) the first client connect, rather extracting the randomness when the server starts.
That advice worries my secure-coding instinct, but I can't quite place why. One concern is about timing attacks -- that you might be able to tell if you're triggering an operation that requires crypto vs. one that doesn't by how long it waits to get randomness. Another is about DoSing the source of random data.
What's the reasonable compromise here? Fetch all the randomness you need at once, but do all that fetching as late as possible?
LCE: Don't play dice with random numbers
Posted Nov 21, 2012 1:20 UTC (Wed) by hpa (guest, #48575) [Link]
However, the dearth of entropy on startup is a real problem unless you have a working HWRNG and applications really should take that into consideration.
LCE: Don't play dice with random numbers
Posted Nov 21, 2012 1:38 UTC (Wed) by dlang (guest, #313) [Link]
For most applications, I think this is less of an issue than most people think. If it's just session encryption keys (SSL, etc) then the timing of the network traffic that initiates the connections will start to provide some randomness (enough that using urandom is not predictable from a practical point of view, even if the more conservative random would block)
The real issue is things like generating server encryption keys on first boot. The answer to this may be something along the lines of not starting the full system on first boot, delaying a known time period (10 seconds or so) to get a bit of entropy (potentially doing other things to try and add entropy), then generating keys and rebooting.
I think that in many cases, people are overthinking the need for 'perfect' randomness, and in the process loosing the 'good enough' security.
LCE: Don't play dice with random numbers
Posted Nov 21, 2012 4:03 UTC (Wed) by vomlehn (guest, #45588) [Link]
LCE: Don't play dice with random numbers
Posted Nov 21, 2012 5:20 UTC (Wed) by hpa (guest, #48575) [Link]
The timing of network traffic that someone mentioned is not very random, and worse, it is potentially observable, which limits its utility.
LCE: Don't play dice with random numbers
Posted Nov 23, 2012 21:23 UTC (Fri) by cesarb (subscriber, #6266) [Link]
Recent kernels have fixed that problem by reading serial numbers and such in the hardware and adding them to the pool on bot.
LCE: Don't play dice with random numbers
Posted Nov 23, 2012 21:37 UTC (Fri) by PaXTeam (guest, #24616) [Link]
LCE: Don't play dice with random numbers
Posted Nov 21, 2012 13:04 UTC (Wed) by etienne (guest, #25256) [Link]
Maybe "root" should be able to see the bare entropy source buffer and the output of the conditioner and of the CSPRNG (or what has been generated in the past) to detect "bugs"/trojan on any computer?
Security by obscurity is not good here.
Having a sysfs file to know how many times the bare entropy has been used and how many time / for how long reads to /dev/random were delayed may be good too.
> There is currently no way to invalidate the randomness pool in the clones
Opening non-blocking the file /dev/random and read it until it blocks does not work? I did not test.
LCE: Don't play dice with random numbers
Posted Nov 21, 2012 18:45 UTC (Wed) by hpa (guest, #48575) [Link]
Therefore, the VMM needs to make the kernel aware that it has been cloned, and make sure the pool diverges from its clone. This can be done by injecting a unique token into the entropy pool of each of the kernel clones as well as setting the entropy count to zero via RNDZAPENTCNT.
This doesn't require any kernel changes but requires a way for the VMM to communicate with the guest and make it do so. The other option is that we add an interface to the (guest) kernel to make it possible for the VMM to do so "from underneath", without invoking guest user space.
LCE: Don't play dice with random numbers
Posted Nov 22, 2012 20:15 UTC (Thu) by kleptog (subscriber, #1183) [Link]
Not sure how you prove its really random though, but at least every image is uncorrelated with every other image.
LCE: Don't play dice with random numbers
Posted Nov 25, 2012 1:26 UTC (Sun) by pr1268 (subscriber, #24648) [Link]
I believe what you've described is a HWRNG based on hardware noise. At least based on my experience with digital photography in low-light situations. Perhaps yours is an unconventional method to gather random values, but what an intriguing technique!
LCE: Don't play dice with random numbers
Posted Nov 25, 2012 6:10 UTC (Sun) by rgmoore (✭ supporter ✭, #75) [Link]
That's a good idea, but some of the implementation details are wrong in a way that might cause real world problems. For one thing, digital cameras sensors* measure the value for only one color at each physical pixel location. The three color final picture is the result of a complex color interpolation routine, which should result in correlation between the values in adjacent pixels. So in practice, you'll want to get the raw, uninterpolated sensor data rather than the final three colors per pixel interpolated data. Also, many real-world sensors have some kind of correlation between nearby pixels that isn't the result of the interpolation routines; it shows up as "pattern noise" in low-light pictures and is a major limit on many cameras' ability to take pictures in low light.
And as long as you're looking only at the least significant digits at each pixel, you shouldn't actually need to cover the lens. The least significant value is subject to shot noise as long as the pixel isn't anywhere close to saturation. Testing to make sure that it isn't saturated should be pretty easy, so you could probably get some useful randomness by appropriate use of a webcam without needing any modification.
*With the exception of those using Foveon's x3 technology, which is limited to a few expensive models you probably aren't going to be using for these applications.
LCE: Don't play dice with random numbers
Posted Nov 25, 2012 7:38 UTC (Sun) by kleptog (subscriber, #1183) [Link]
For example, if you have 50kB of data that you know has 50% entropy you can "distill" it. The trick is knowing the 50%.
You're right you don't need to cover the lens, I left that out for simplicity. I tried this out on a camera being used for another purpose. It had some light and some dark, and the "randomness" was clearly dependant on the light level at that point. But like you say the camera has internal processing (to handle e.g. varying light conditions) and it's hard to know what effect that is having on the output.
Raw output would be best, but I don't know if cheap webcams offer that :)
LCE: Don't play dice with random numbers
Posted Nov 26, 2012 4:23 UTC (Mon) by rgmoore (✭ supporter ✭, #75) [Link]
Raw output would be best, but I don't know if cheap webcams offer that :)
I think that raw output is going to be pretty much mandatory if you hope to get anything like the theoretical entropy out of the sensor. But thinking about it, the biggest loss won't be from interpolation, it will be from using lossy compression. An essential trick to the lossy compression algorithms used to send images and video is that they keep only the most significant information in the picture. Since you're hoping to use the least significant information as a source of entropy, that's a killer.
LCE: Don't play dice with random numbers
Posted Nov 23, 2012 1:24 UTC (Fri) by dirtyepic (guest, #30178) [Link]
I was bringing up a new laptop last weekend and noticed a message in the boot log that no hardware RNG was found which I thought was odd. I don't seem to have a /dev/hwrng either. I wonder if I configured something incorrectly.
LCE: Don't play dice with random numbers
Posted Nov 23, 2012 9:38 UTC (Fri) by etienne (guest, #25256) [Link]
LCE: Don't play dice with random numbers
Posted Nov 23, 2012 20:03 UTC (Fri) by nix (subscriber, #2304) [Link]
LCE: Don't play dice with random numbers
Posted Nov 23, 2012 20:35 UTC (Fri) by bjencks (subscriber, #80303) [Link]
However, most applications get their entropy from /dev/[u]random, so for them to benefit you need to feed the kernel pools from it. Modern rngd does this by calling the instruction directly in user-mode and then pushing the entropy to the kernel. Additionally, as described in the article, if you have a 3.6+ kernel with "Architectural RNG" enabled, it xors rdrand output with all random and urandom reads.
You can check if rdrand is available with "grep rdrand /proc/cpuinfo".
LCE: Don't play dice with random numbers
Posted Nov 24, 2012 6:05 UTC (Sat) by dirtyepic (guest, #30178) [Link]
Thanks for the info. With 3.6 it seems to be working.# rngd -v Available entropy sources: DRNG TPM
LCE: Don't play dice with random numbers
Posted Nov 25, 2012 16:59 UTC (Sun) by gmaxwell (guest, #30048) [Link]
The kernel entropy pool is quite small (4kbits). It used to be possible to resize it without rebuilding the kernel and rebooting but the resize api had an exploitable vulnerablity so it was removed. Concurrently, concerns about the quality of the random data from most drivers resulted in their contributions from the pool being removed.
So on many non-desktop systems you ~only get the 100hz timer input and can't even stock up much randomness. With things like apache and ssh reading /dev/random by default this results in a lot of mysterious slowness for things like SSH logins.
I'm surprised that I haven't to be much interest or discussion in doing anything about this outside of virtualization (which has it only slightly worse than many systems).
Of course, it's usually not hard to replace random with urandom but for systems that do sometimes generate long term keys thats a bit less than ideal.
LCE: Don't play dice with random numbers
Posted Nov 25, 2012 17:15 UTC (Sun) by gmaxwell (guest, #30048) [Link]
LCE: Don't play dice with random numbers
Posted Nov 26, 2012 22:19 UTC (Mon) by BenHutchings (subscriber, #37955) [Link]
...concerns about the quality of the random data from most drivers resulted in their contributions from the pool being removed.
This was also changed recently: all IRQs now contribute to the random pool, but with very little entropy credited (something like 1 bit per 64 IRQs).
LCE: Don't play dice with random numbers
Posted Nov 27, 2012 8:44 UTC (Tue) by kleptog (subscriber, #1183) [Link]
Lots of Random B.S.
Posted Dec 2, 2012 2:03 UTC (Sun) by BrucePerens (guest, #2510) [Link]
There is never, and can not possibly ever be, a need for a hardware random noise generator more complicated than a single diode junction followed by an appropriate detector. The avalanche phenomenon is quantum mechanical. Lava Lamp random number generators are toys to impress the technically naive. Gates with "impossible states" are not an improvement upon the diode.
Lots of Random B.S.
Posted Dec 3, 2012 1:33 UTC (Mon) by rgmoore (✭ supporter ✭, #75) [Link]
I think the Intel crew give a good explanation for exactly why they want to use the system they do. It's a straight digital system that doesn't rely on any analog circuitry, so it easy to incorporate into a CPU without having to worry about the behavior of the circuit changing when you change fabrication process. It also looks like a dead simple design, so it may be easier to fabricate in practice than anything based on an avalanche diode.
LCE: Don't play dice with random numbers
Posted Dec 3, 2012 17:23 UTC (Mon) by Kaejox (guest, #85586) [Link]
It's possible to plug in hardware based RNG Simtec Entropy Key (USB stick) that keeps entropy pool full, so existing systems can benefit from steady stream of good random numbers.
http://www.entropykey.co.uk/
LCE: Don't play dice with random numbers
Posted Dec 3, 2012 18:32 UTC (Mon) by madhatter (subscriber, #4665) [Link]
LCE: Don't play dice with random numbers
Posted Dec 4, 2012 15:46 UTC (Tue) by nix (subscriber, #2304) [Link]
LCE: Don't play dice with random numbers
Posted Dec 4, 2012 11:43 UTC (Tue) by alex2 (guest, #73934) [Link]
HAVEGE
Posted Oct 12, 2015 20:05 UTC (Mon) by bnhy (guest, #104885) [Link]
Um, that seems like a weird test. If we had a machine that output apple pies and claimed to use genuine apples, wouldn't it seem more logical to examine whether real apples were an actual input rather than tasting the output to see if it tasted like apples? Put another way, why wouldn't you examine the data HAVEGE feeds its internal PRNG rather than testing the output of the PRNG? It seems like the test was designed with a certain conclusion in mind.
LCE: Don't play dice with random numbers
Posted Mar 29, 2016 1:00 UTC (Tue) by iment (guest, #107919) [Link]
For example, a random number is (represented by) a sequence of digits which cannot be generated by a program which is significantly shorter than that sequence. In other words, the shortest program to generate the number has to have the number as a built-in constant. This essentially says that algorithmic random number generators don't generate true random sequences (even before they repeat).
This is the view of complexity and randomness put forth by Kolmogorov and Chaitin (https://en.wikipedia.org/wiki/Kolmogorov_complexity).
LCE: Don't play dice with random numbers
Posted Mar 29, 2016 15:07 UTC (Tue) by raven667 (subscriber, #5198) [Link]
True, but they do allow you to stretch out the use of a real random number that's less than a kilobyte to cover the needs of gigabytes or terabytes of data.