The best open source software of 2021
InfoWorld’s 2021 Bossie Awards recognize the year’s best open source software for software development, devops, data analytics, and machine learning.































InfoWorld’s 2021 Bossie Award Winners
Money may not grow on trees, but it does grow in GitHub repos. Open source projects produce the most valuable and sophisticated software on the planet, free for the taking, dramatically lowering the costs of information technology for all companies. If you’re looking for the cutting edge in software, look to today’s open source projects.
You’ll find 28 of those edge cutters right here, in InfoWorld’s 2021 Best of Open Source Software Awards. Our 2021 Bossie Award winners represent the very best and most innovative software—for software development, devops, cloud-native computing, machine learning, and more—that today’s open source has to offer.
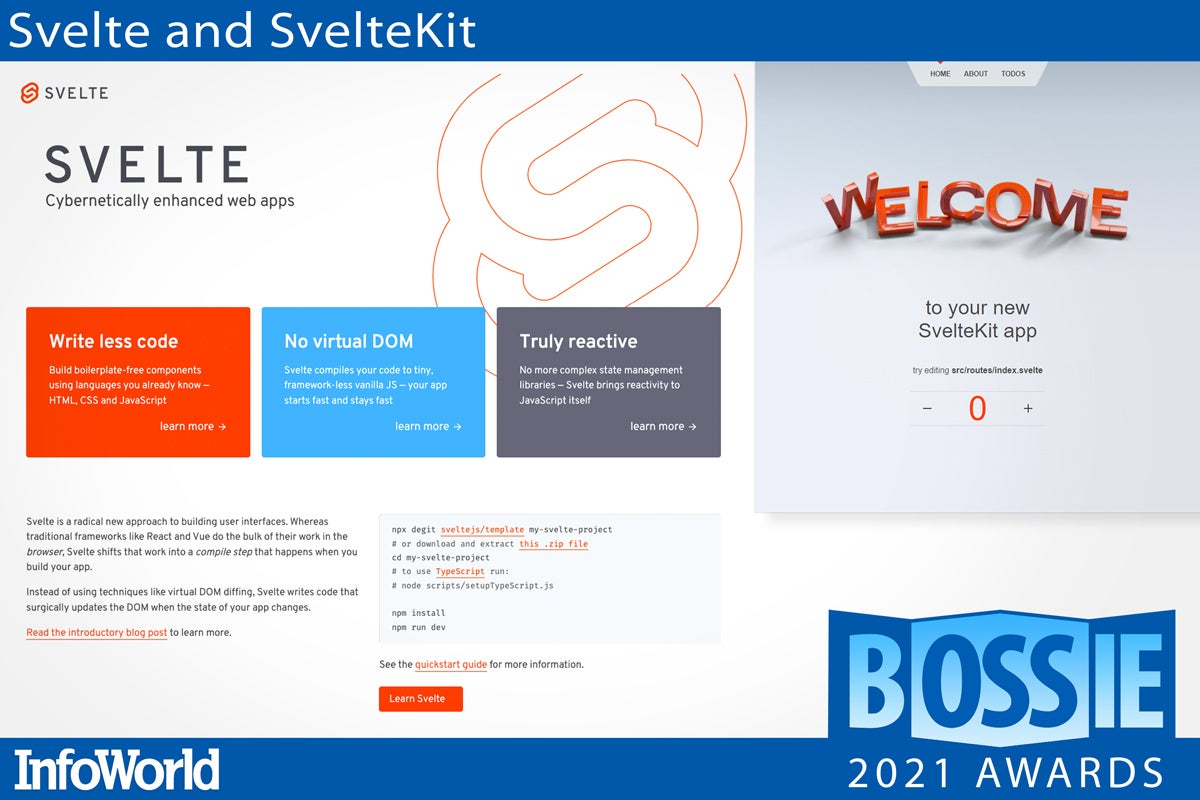
Svelte and SvelteKit
In a field of innovative, open source, front-end JavaScript frameworks, Svelte and its full-stack counterpart SvelteKit are perhaps the most ambitious and visionary of all. Svelte began by upsetting the status-quo by adopting a compile-time strategy, and has moved forward with excellent performance, continued evolution, and a superior developer experience. SvelteKit, now making its way through public beta, continues the Svelte tradition of taking leaps by adopting the most recent tooling and making deployment to serverless environments a built-in feature.
— Matthew Tyson

Minikube
If Docker Desktop has become a non-starter because of its new pricing and licensing requirements, consider Minikube. As the name implies, Minikube is a miniature Kubernetes cluster that runs on the desktop. No virtual machine is required; Minikube will work with native containers or on bare metal. You don’t need a Linux distribution on MacOS or Windows to get things running, either; Minikube works cross-platform. It also supports multiple container runtimes (Docker, CRI-O, or Containerd). A whole host of continuous integration platforms work natively with Minikube. The best part is that because it’s Kubernetes, you can use the tools and components from Kubernetes itself if you need to.
— Serdar Yegulalp
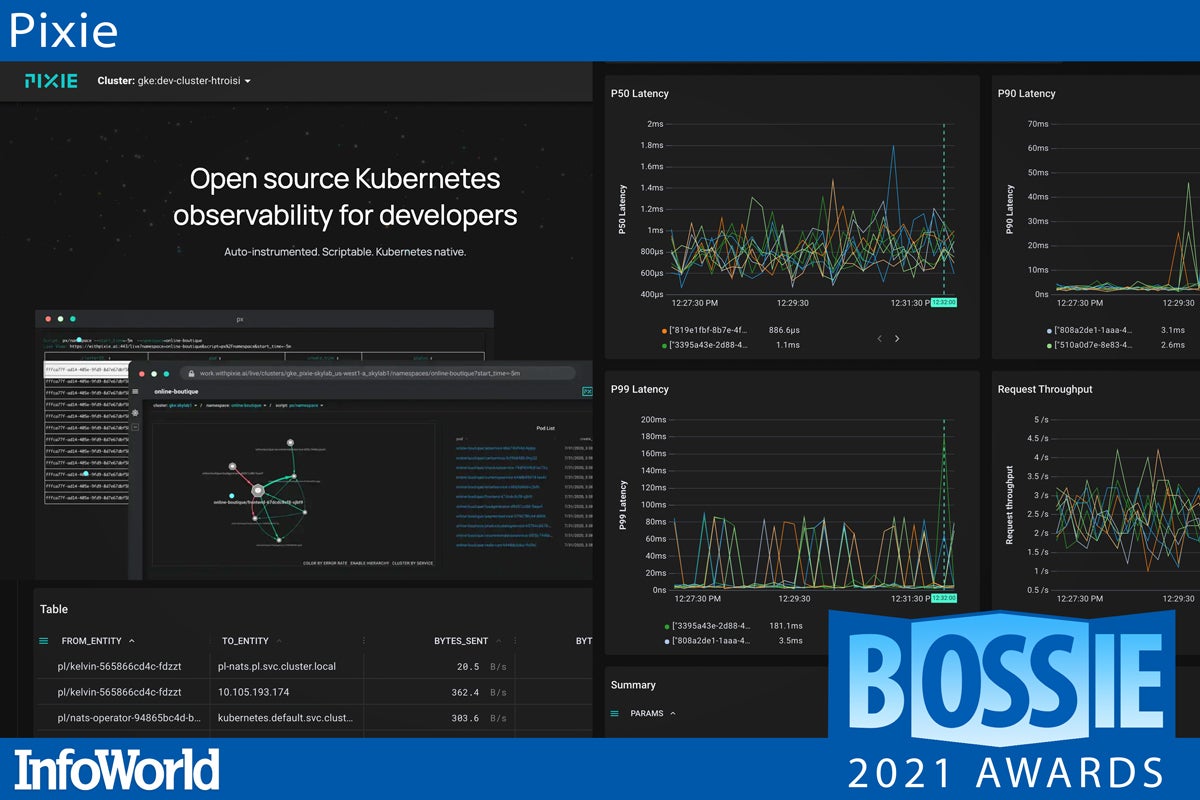
Pixie
Pixie is an observability tool for Kubernetes applications, which can view the high-level state of your cluster, such as service maps, cluster resources, and application traffic, and also drill down into more detailed views, such as pod state, flame graphs, and individual full-body application requests. Pixie uses eBPF to automatically collect telemetry data, and it collects, stores and queries all telemetry data locally in the cluster, using less than 5% of cluster CPU. Use cases for Pixie include network monitoring within a cluster, infrastructure health, service performance, and database query profiling.
— Martin Heller

FastAPI
Django and Flask have been the leading Python web frameworks for years. FastAPI now deserves to be mentioned in the same breath. FastAPI does more than compete with those web frameworks for speed of development and execution — although it definitely does that. FastAPI is a truly modern Python web framework, written from the ground up to use type hinting, async, and high-speed components by default. As the name implies, one of the common use cases for FastAPI is quickly standing up standards-compliant and powerful web APIs. But FastAPI is equally well-suited to building more conventional websites.
— Serdar Yegulalp
Crystal
A project to deliver a programming language with the speed of C and the expressiveness of Ruby, Crystal has been in development for some years now. With the release of Crystal 1.0 early this year, the language is now stable enough to use for general workloads. Crystal uses static typing and the LLVM compiler to achieve high speeds and to avoid common problems like null references at runtime. Crystal can interface with existing C code for further speed and convenience, and it can use compile-time macros to extend the base language syntax.
— Serdar Yegulalp
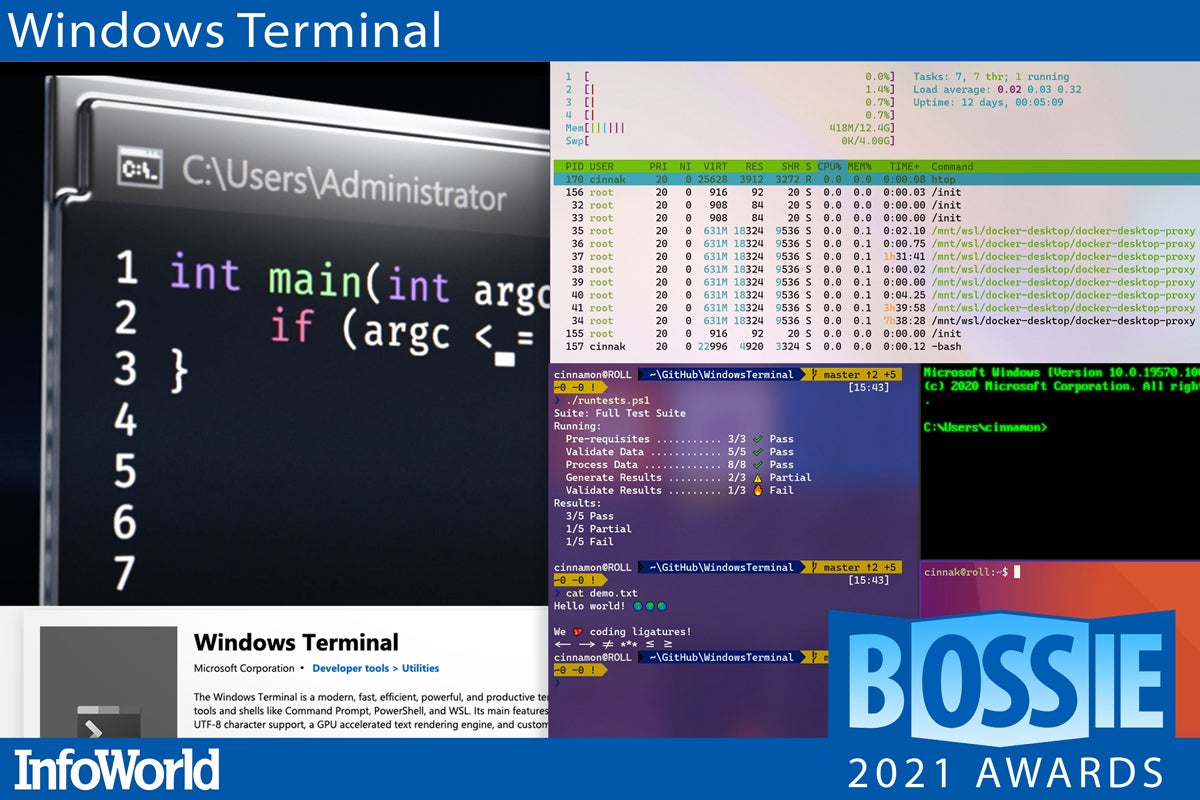
Windows Terminal
If any part of Microsoft Windows badly needs an update, it’s the slow, inflexible, antiquated console host—the component that renders command-line applications in a text window. Enter Windows Terminal, an open source terminal application designed to give Windows users a command-line experience akin to what Mac and Linux users have long enjoyed. GPU-accelerated rendering gives an orders-of-magnitude performance boost over the older console host, and configuration options let you customize terminal appearance and behavior in ways never possible before. Windows Terminal hasn’t replaced the old console host in Windows quite yet, but give it time.
— Serdar Yegulalp
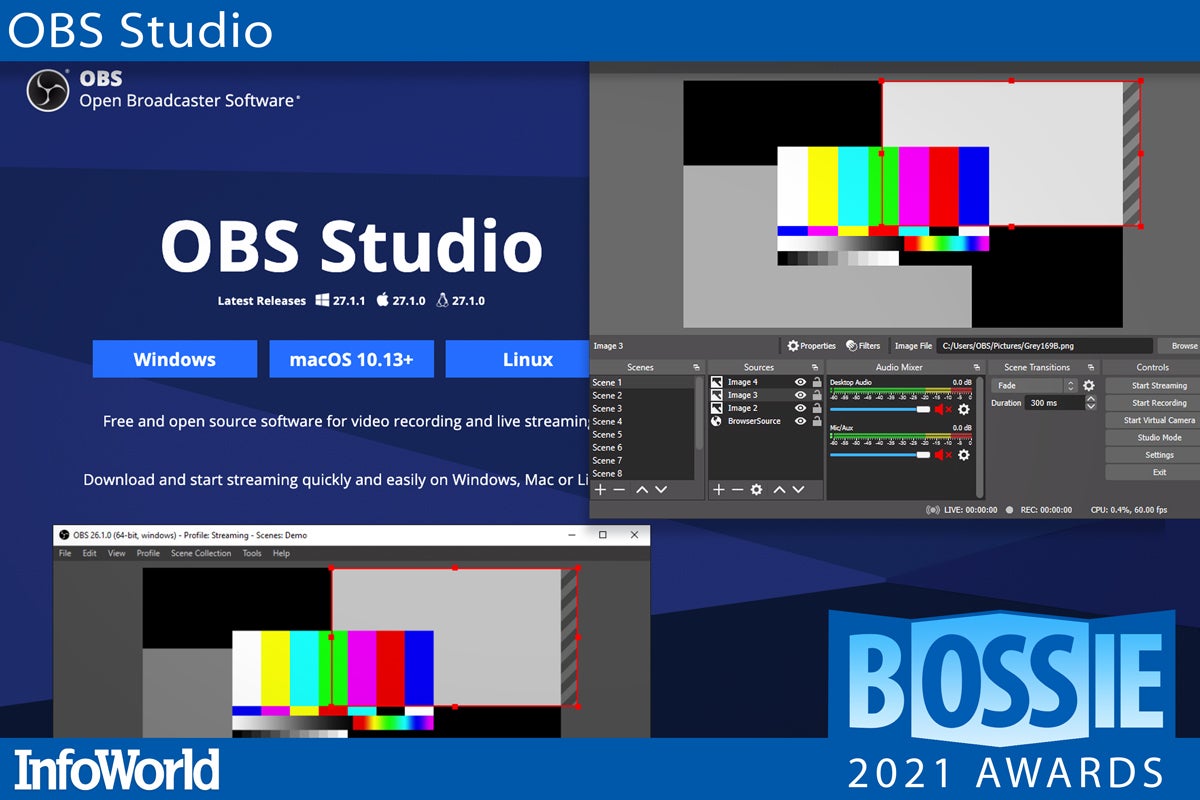
OBS Studio
Video capture and live streaming were already big before the pandemic years, and now they’re doubly important. OBS Studio stands head and shoulders above even commercial display capture and camera recording suites. Users can create multiple capture source definitions (live camera, full desktop, specific window), save captures to files on disk, or stream them in real time to a provider. Hotkey controls let you transition smoothly between views, so you don’t have to capture multiple streams and edit them together. Picture-in-picture effects and even live captioning (although that’s still experimental) are also included.
— Serdar Yegulalp
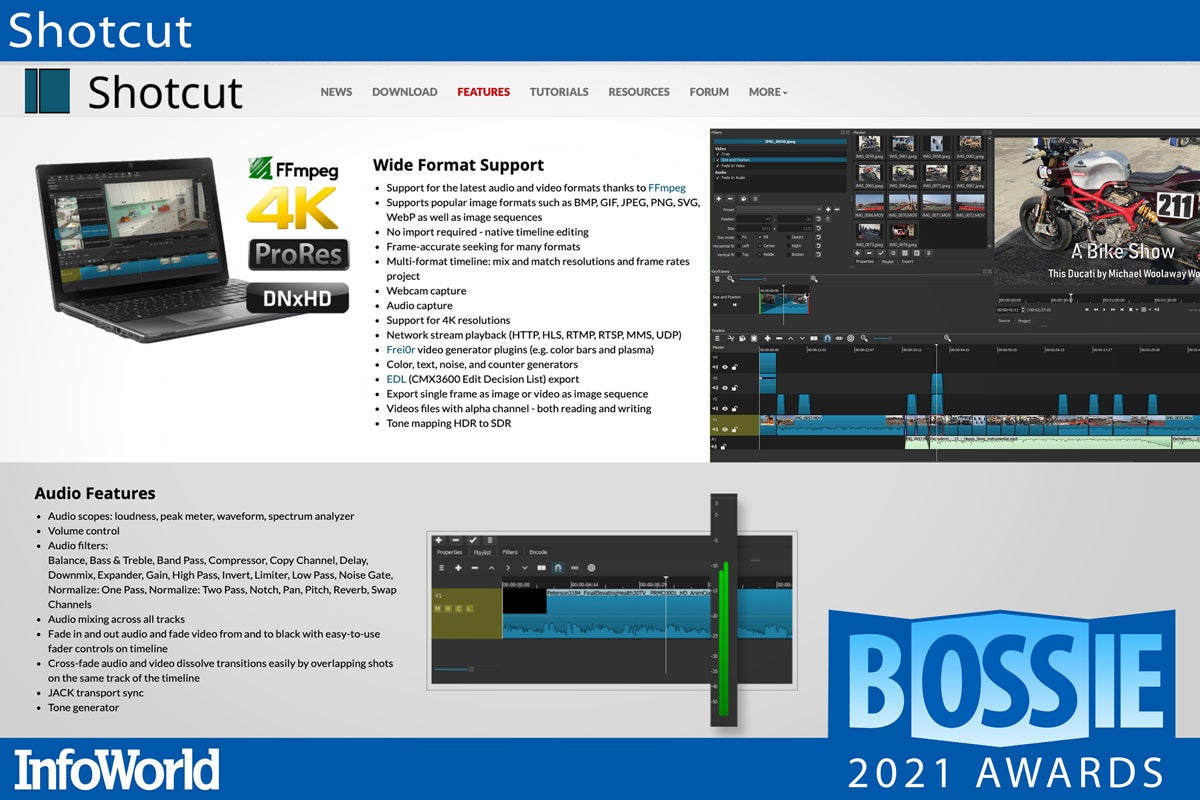
Shotcut
Shotcut is a cross-platform tool for video editing that is giving Davinci Resolve a run for its money. Shotcut allows one to do all of the standard corrections on audio and video tracks along with applying effects and layering. Shotcut has a really vibrant community, and offers plenty of how-to videos and guidance to help novices and advanced videographers alike. It runs on Mac, Linux, BSD, and Windows — and despite being cross-platform, the interface is snappy and relatively simple to use compared to similar tools.
— Andrew C. Oliver

Weave GitOps Core
Weave GitOps Core is a tool for doing GitOps. GitOps allows you to declare your configuration in Git and have it applied by an agent to your Kubernetes cluster. The idea is both to simplify your devops workflow and to make your configuration more stable and secure by preventing configuration drift. Central to the latter is the “reconciliation engine,” which detects changes in the Git declared state and migrates the configuration changes to the runtime environment. Weave GitOps is based on Flux, the Cloud Native Computing Foundation’s reference implementation of GitOps.
— Andrew C. Oliver

Apache Solr
Apache Solr is a long-lived search platform built on Apache Lucene. Apache Lucene is the underlying search technology behind the search functionality of probably most of the software you use — including other search engines such as Elasticsearch. Unlike Elasticsearch, which dropped its open source license, Solr is still free. Solr is clusterable, cloud deployable, and powerful enough to build cloud-grade search services on. It even includes the learning to rank (LTR) algorithm to help automatically tune and weight results.
— Andrew C. Oliver
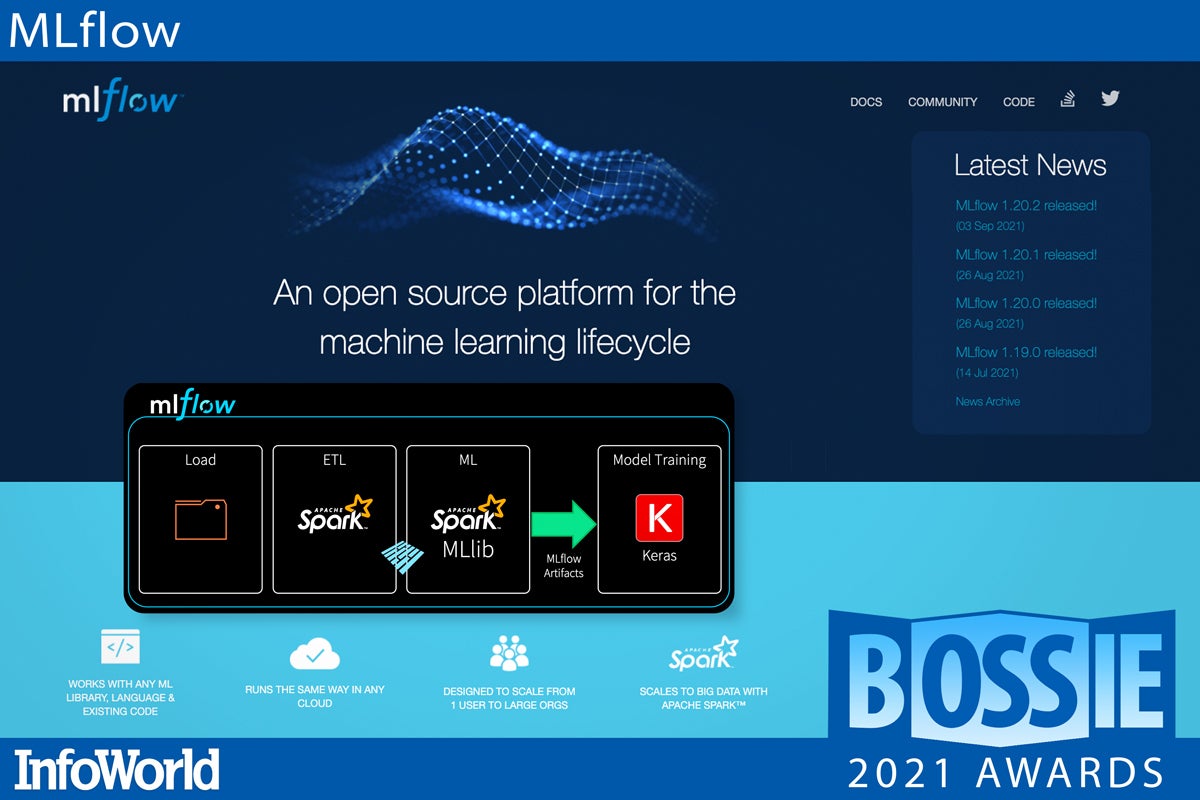
MLflow
When a technology domain becomes popular and complex enough — with lots of moving parts and lots of people involved — it ends up having an equally complex operations or “ops” counterpart. Machine learning is no different, and hence we have “MLOps.” Created by Databricks, and hosted by the Linux Foundation, MLflow is an MLOps platform that lets one track, manage, and maintain various machine learning models, experiments, and their deployments. It gives you tools to record and query experiments (code, data, config, results), package data science code into projects, and chain these projects into workflows. Think devops and lifecycle management for machine learning.
— Andrew C. Oliver

Orange
Orange promises to make data mining “fruitful and fun.” It has a lineage going back almost a quarter of a century but is still in wide use and active development today. Orange allows users to create a data analysis workflow and perform all kinds of machine learning and analysis functions as well as visualizations. In contrast to programmatic or textual tools like R Studio and Jupyter, Orange is very visual. You drag widgets onto a canvas to load a file, analyze data with a model, and visualize the results. Users with a serpentine inclination can use the Python script widget to manipulate data programmatically.
— Andrew C. Oliver
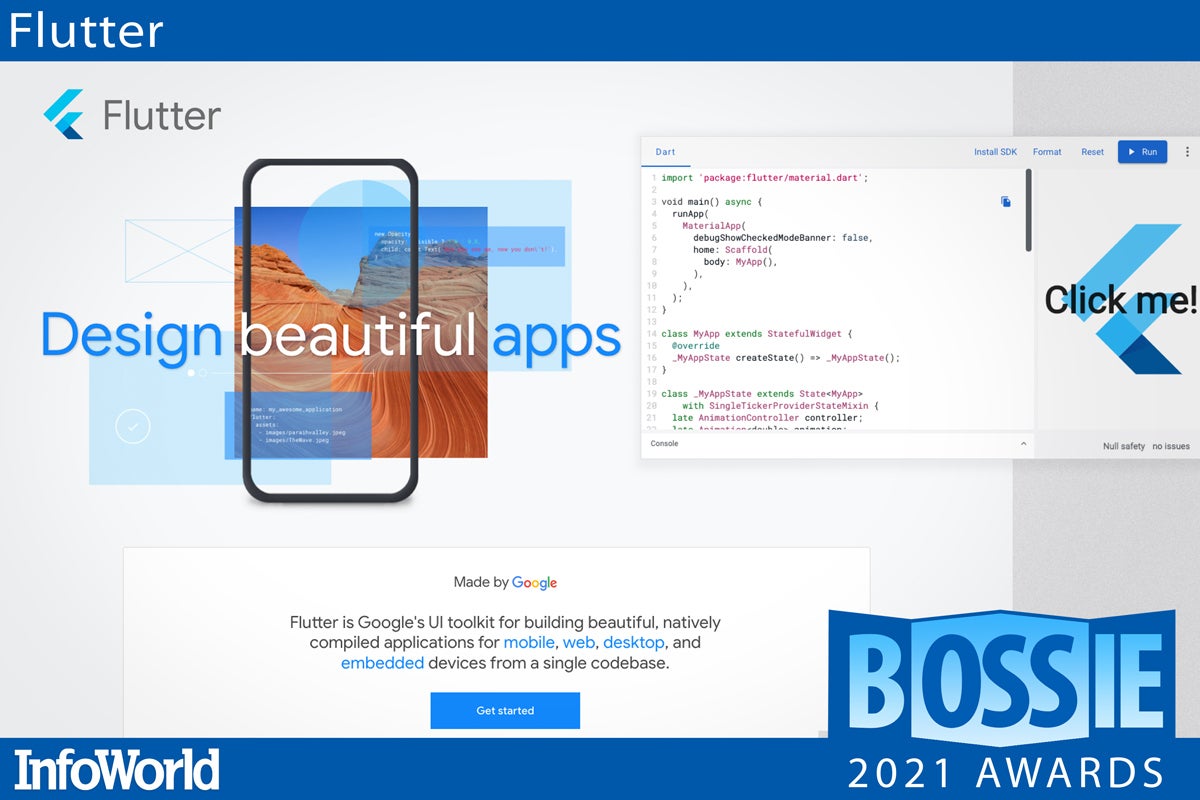
Flutter
Flutter is Google’s UI toolkit for building natively compiled applications for mobile, web, desktop, and embedded devices from a single codebase. It is based on the Dart language and a rich set of fully customizable Material Design and Cupertino-style widgets to build native interfaces. Flutter’s widgets incorporate all critical platform differences such as scrolling, navigation, icons, and fonts to provide full native performance on both iOS and Android.
— Martin Heller

Apache Superset
Apache Superset is a modern, enterprise-ready, business intelligence web application. It is fast, lightweight, and easy to use, allowing users of all skill sets to explore and visualize their data, from simple pie charts to highly detailed deck.gl geospatial charts. Superset provides an intuitive interface for visualizing datasets and crafting interactive dashboards, a wide array of data visualizations, a code-free visualization builder, and a SQL IDE for preparing data for visualization. And on the back end, you’ll find support for most SQL-speaking databases, in-memory asynchronous caching and queries, and a cloud-native architecture designed from the ground up for scale.
— Martin Heller

Presto
Presto is an open source, distributed SQL engine for online analytical processing that runs in clusters. Presto can query a wide variety of data sources, from files to databases, and return results to many BI and analysis environments. What’s more, Presto allows querying data where it lives, including Hive, Cassandra, relational databases, and proprietary data stores. A single Presto query can combine data from multiple sources. Facebook uses Presto for interactive queries against several internal data stores, including their 300PB data warehouse.
The Presto Foundation is the organization that oversees the development of the Presto open source project. Facebook, Uber, Twitter, and Alibaba founded the Presto Foundation. Additional members now include Alluxio, Ahana, Upsolver, and Intel.
— Martin Heller
Apache Arrow
Apache Arrow defines a language-independent columnar memory format for flat and hierarchical data, organized for efficient analytic operations on modern CPUs and GPUs. The Arrow memory format also supports zero-copy reads for lightning-fast data access without serialization overhead. The contiguous columnar layout enables vectorization using the latest SIMD (single instruction, multiple data) operations included in modern processors.
Arrow’s libraries implement the format and provide building blocks for a range of use cases, including high performance analytics. Many popular projects use Arrow to ship columnar data efficiently or as the basis for analytic engines. Arrow libraries are available for C, C++, C#, Go, Java, JavaScript, Julia, MATLAB, Python, R, Ruby, and Rust.
— Martin Heller

InterpretML
Explainable AI (XAI), also called interpretable AI, refers to machine learning and deep learning methods that can explain their decisions in a way that humans can understand. The hope is that XAI will eventually become just as accurate as black-box models. InterpretML is an open source XAI package that incorporates several state-of-the-art machine learning interpretability techniques. InterpretML lets you train interpretable models and explain black box systems. InterpretML helps you understand your model’s global behavior and the reasons behind individual predictions. Among its many features, InterpretML has a “glass box” model from Microsoft Research called the Explainable Boosting Machine, and it supports Lime for post-hoc explanations by approximations of black-box models.
— Martin Heller
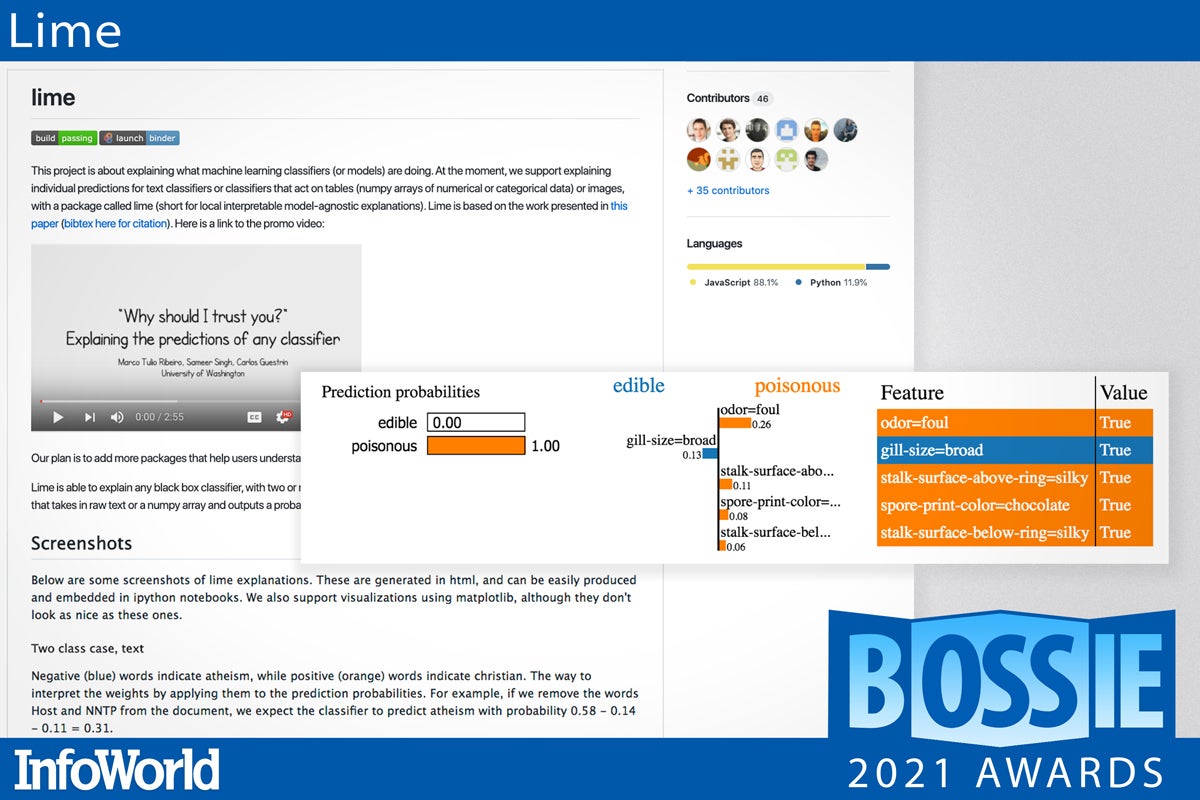
Lime
Lime (short for local interpretable model-agnostic explanations) is a post-hoc technique to explain the predictions of any machine learning classifier by perturbing the features of an input and examining the predictions. The key intuition behind Lime is that it is much easier to approximate a black box model by a simple model locally (in the neighborhood of the prediction we want to explain) than to try to approximate a model globally. Lime applies to both the text and image domains. The Lime Python package is available on PyPI with source on GitHub, and it’s also included in InterpretML.
— Martin Heller

Dask
Dask is an open source library for parallel computing that can scale Python packages to multiple machines. Dask can distribute data and computation over multiple GPUs, either in the same system or in a multi-node cluster. Dask integrates with Rapids cuDF, XGBoost, and Rapids cuML for GPU-accelerated data analytics and machine learning. It also integrates with NumPy, Pandas, and Scikit-learn to parallelize their workflows.
— Martin Heller
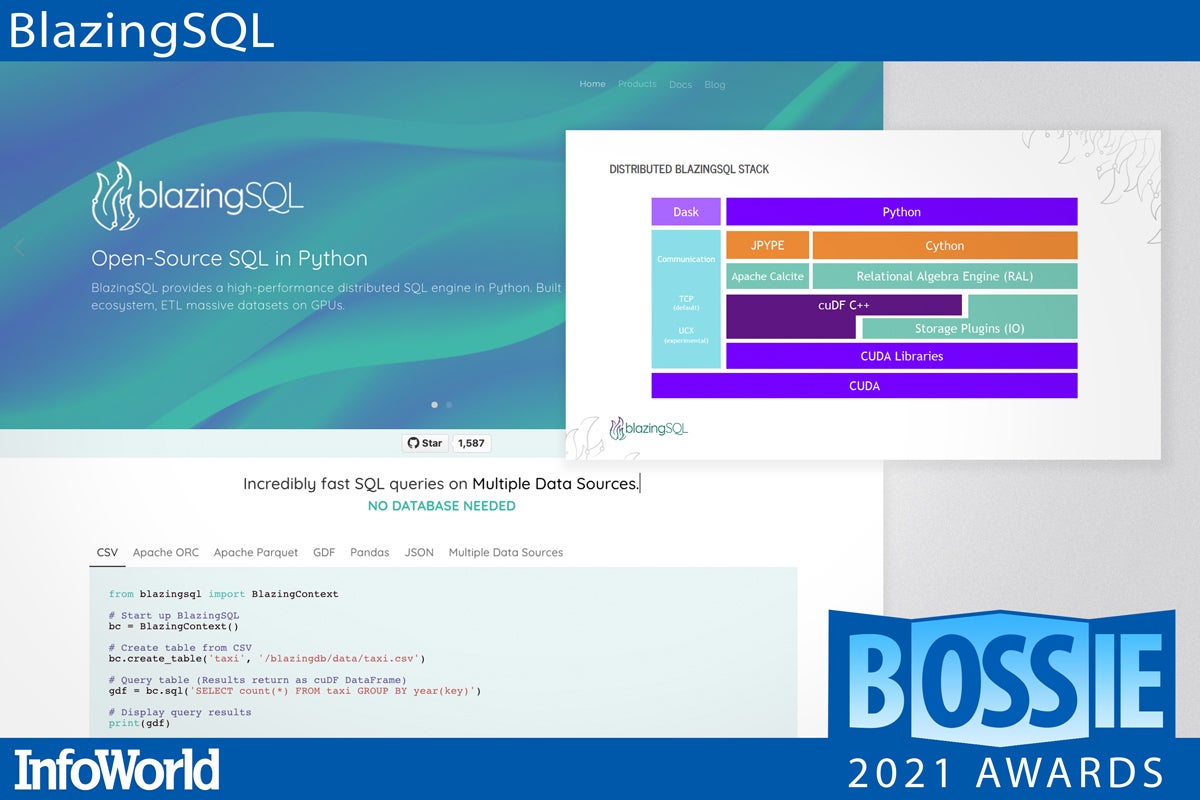
BlazingSQL
BlazingSQL is a GPU-accelerated SQL engine built on top of the Rapids ecosystem. The BlazingSQL code is an open source project released under the Apache 2.0 license. Blazing Notebooks is a cloud service, built on AWS, that combines BlazingSQL, Rapids, and JupyterLab. Basically, BlazingSQL provides the ETL (extract, transform, and load) portion of an all-GPU data science workflow. Once you have GPU DataFrames in GPU memory, you can use Rapids cuML for machine learning, or convert the DataFrames to DLPack or NVTabular for in-GPU deep learning with PyTorch or TensorFlow.
— Martin Heller

Rapids
Nvidia’s Rapids suite of open source software libraries and APIs gives you the ability to execute end-to-end data science and analytics pipelines entirely on GPUs. Rapids uses Nvidia CUDA primitives for low-level compute optimization, and exposes GPU parallelism and high-bandwidth memory speed through user-friendly Python interfaces. Rapids depends on the Apache Arrow columnar memory format and includes cuDF, a Pandas-like dataframe manipulation library; cuML, a collection of machine learning libraries that provides GPU versions of most algorithms available in Scikit-learn; and cuGraph, a NetworkX-like library for accelerated graph analytics.
— Martin Heller
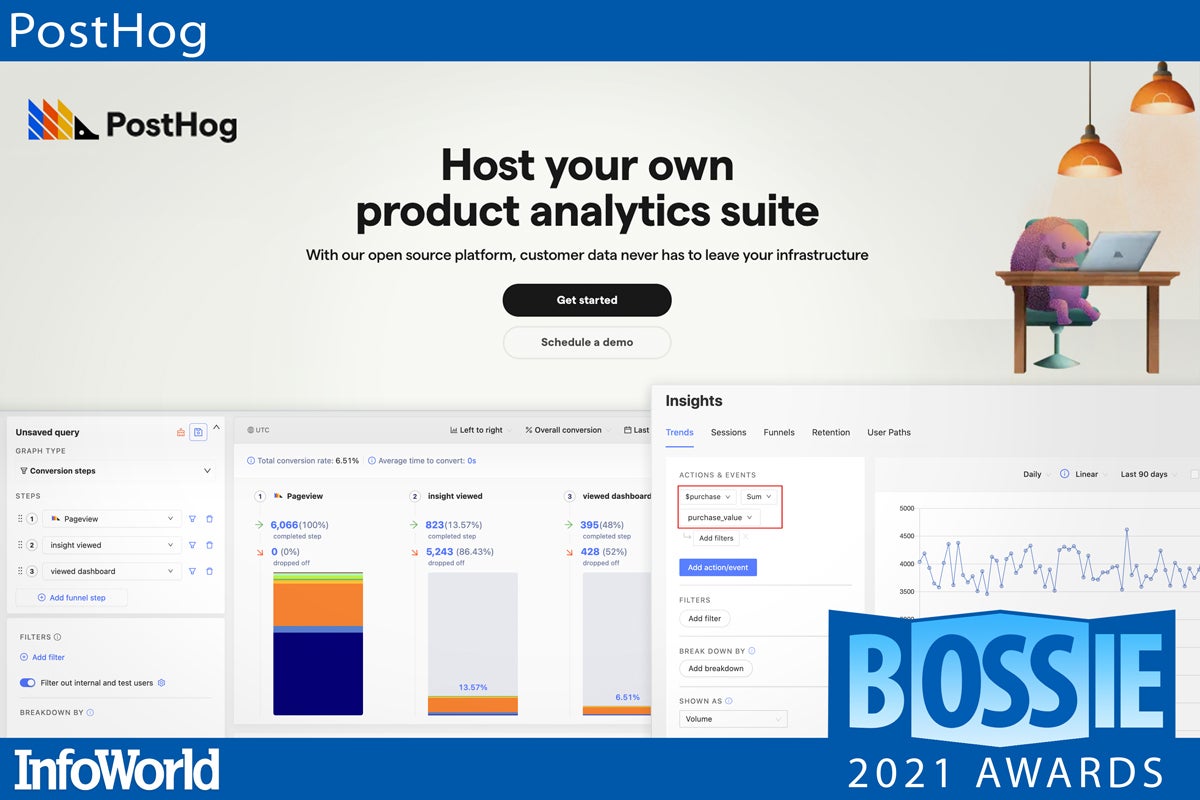
PostHog
PostHog is an easy-to-use instrumentation framework for product analytics, offering a fast path to gaining insight into user behavior of your web and mobile apps. Just add a small JavaScript snippet to your code and you’re off and running. PostHog’s auto-capture collects the deluge of front-end interaction events that fire off during a user session. A point-and-click, menu-driven UI makes easy work of distilling that flood of event data into meaningful action metrics, trend charts, and bite-sized dashboards. Funnels help you refine compound usage patterns even further to isolate bottlenecks and improve bounce rates. Available for on-prem deployment or in a SaaS offering, PostHog takes the tedium and guesswork out of optimizing the user experience of your software products.
— James R. Borck
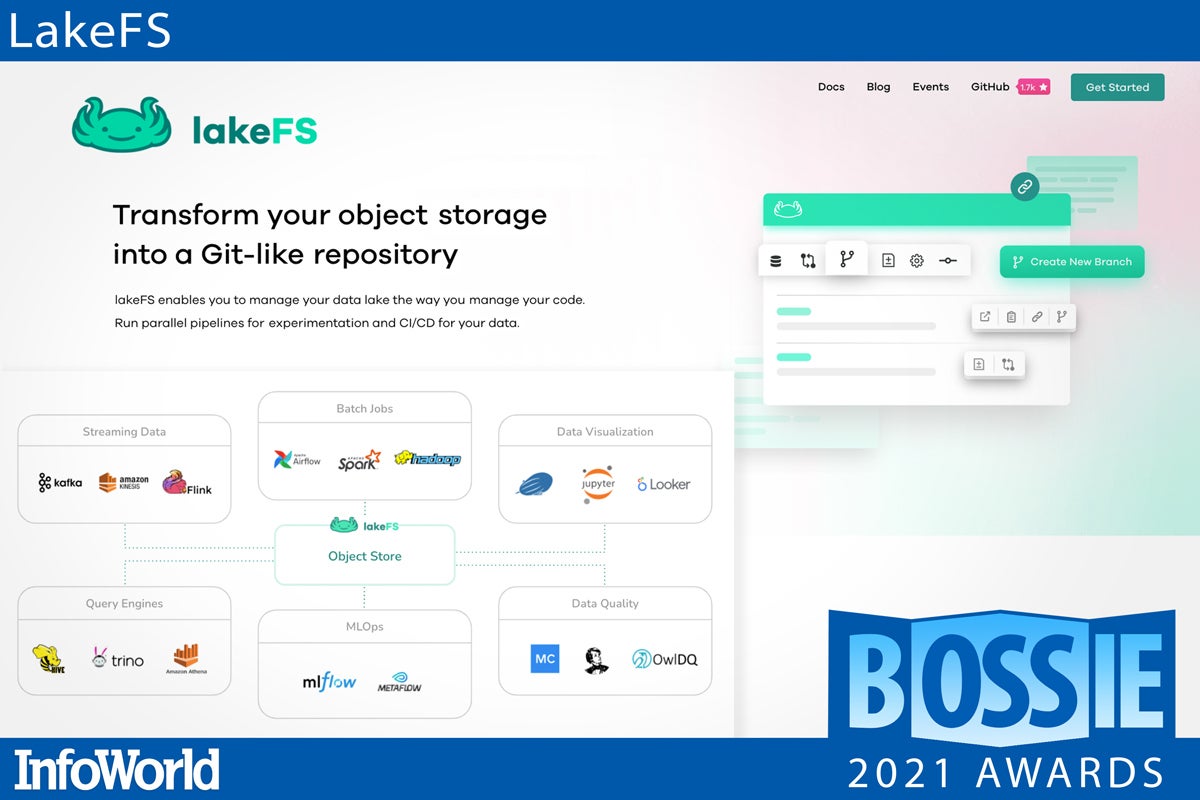
LakeFS
Providing a way to “manage your data lake the way you manage your code,” LakeFS adds a layer of Git-like versioning controls to object storage. This application of Git semantics to data lets users create their own isolated, zero-copy data branches on which to work, experiment, and model analyses, without the risk of corrupting shared objects. LakeFS brings useful commit notes, metadata fields, and rollback options to your data, along with validation hooks to maintain data integrity and quality — running format and schema checks before an uncommitted branch is accidentally merged back into production. With LakeFS, the familiar techniques to manage and protect code repositories can be extended to modern data repositories like Amazon S3 and Azure Blob Storage.
— James R. Borck

Meltano
Spun out of GitLab this year, Meltano is a free, open source, “DataOps” alternative to the traditional ELT (extract, load, transform) toolchain. Meltano’s data warehouse framework makes it easy to model, extract, and transform data for your project, and supplements the integration and transformation pipeline with built-in analysis tools and dashboards that simplify reporting. Providing a solid library of extractors and loaders, as well as support for the Singer standard for data extracting taps and data loading targets, Meltano is already a powerhouse for data orchestration.
— James R. Borck
Trino
Trino — formerly known as PrestoSQL — is a distributed SQL analytics engine capable of running blazingly fast queries against large distributed data sources. Trino allows you to execute queries against data lakes, relational stores, or across a number of different sources simultaneously, without needing to copy or move data for processing. And Trino plays well with whatever BI and analytics tools your data scientists might be using, whether interactive or ad hoc, minimizing the learning curve. As data engineers strive to support increasingly complex analyses across an ever-growing number of data sources, Trino provides a way to optimize query execution and speed results from disparate sources.
— James R. Borck
StreamNative
StreamNative is a highly scalable messaging and event streaming platform that greatly simplifies laying data pipelines for real-time reporting and analytics tools, as well as for streaming enterprise applications. Combining the powerful distributed stream processing architecture of Apache Pulsar with enterprise extras like Kubernetes and hybrid-cloud support, a large data connector library, easy authentication and authorization, and dedicated tools for health and performance monitoring, StreamNative both eases the development of Pulsar-based real-time applications and simplifies the deployment and management of a large-scale messaging backplane.
— James R. Borck

Hugging Face
Hugging Face offers the most important open source deep learning repository that isn’t a deep learning framework itself. The project’s total command of the Transformers-based landscape continues to increase, with new models being added to the repo mere days after papers are published. Model hosting is going from strength to strength, and new work such as Accelerate makes it easier to use distributed GPU training. Now Hugging Face’s sights are set on expanding well beyond text with support for images, audio, video, object detection, and more. Deep learning practitioners will be keeping a close eye on this repo for years to come.
— Ian Pointer
EleutherAI
OpenAI’s GPT-3 model is an amazing leap forward in text generation, capable of human-level performance. But, although limited access is available via API, the trained version of GPT-3 is fully accessible only to OpenAI and Microsoft. Enter EleutherAI, a distributed group of machine learning researchers driven to bring GPT-3 to the rest of us. To kick off 2021, EleutherAI released The Pile, a massive 825 gigabyte dataset of diverse text for training, and in June the group unveiled GPT-J, a six billion parameter model roughly equivalent to OpenAI’s Curie variant of GPT-3. With GPT-NeoX, EleutherAI plans to go all the way to 175 billion parameters to compete with the most expansive GPT-3 model currently available. Hackers taking on the biggest companies in the world? That’s the power of open source.
— Ian Pointer

Colab notebooks for generative art
The winners of the Bossies have traditionally been libraries, frameworks, platforms, and operating systems — the backbone of open source. However, I think the open source components that have ignited this year’s explosion in generative art also deserve some recognition. First up, there’s OpenAI’s CLIP (Contrastive Language-Image Pre-training) model, a multimodal model for generating text and image vector embeddings. While CLIP was fully open sourced, OpenAI’s generative neural network, DALL-E, was not. To fill that gap, Ryan Murdoch and Katherine Crowson developed Colab notebooks that combined CLIP with other open source models, such as BigGAN and VQGAN, to make prompt-based generative artworks. And these notebooks, themselves free to use under an MIT license, have spread across the internet like fanzines of decades past, being remixed, altered, translated, and used to produce astonishing works of art. Check out ai_curio on Twitter for an endless stream of examples.
— Ian Pointer
Copyright © 2021 IDG Communications, Inc.